Apache Burr: надёжные AI-агенты на чистом Python
Apache Burr — легковесный Python-фреймворк для надёжных AI-агентов с управлением состоянием, встроенным UI и интеграцией с LangChain, LlamaIndex.
Почему существующих фреймворков недостаточно?
Вы запускаете LLM-приложение в продакшене. Агент звонит в API, принимает решения, пишет в базу. И вдруг — сбой на шаге 7 из 12. Что случилось? Какое состояние было у агента? Можно ли воспроизвести ошибку?
Именно здесь большинство популярных фреймворков пасуют. Существующие решения либо слишком тяжеловесны (как Apache Airflow для оркестрации), либо привязаны к проприетарным экосистемам, либо требуют кастомного кода, который накапливает технический долг.
Apache Burr (Incubating) упрощает разработку приложений, принимающих решения — от простых чат-ботов до сложных мультиагентных систем. При этом фреймворк делает ставку на предсказуемость, наблюдаемость и тестируемость — три свойства, без которых AI-агент в продакшене превращается в «чёрный ящик».
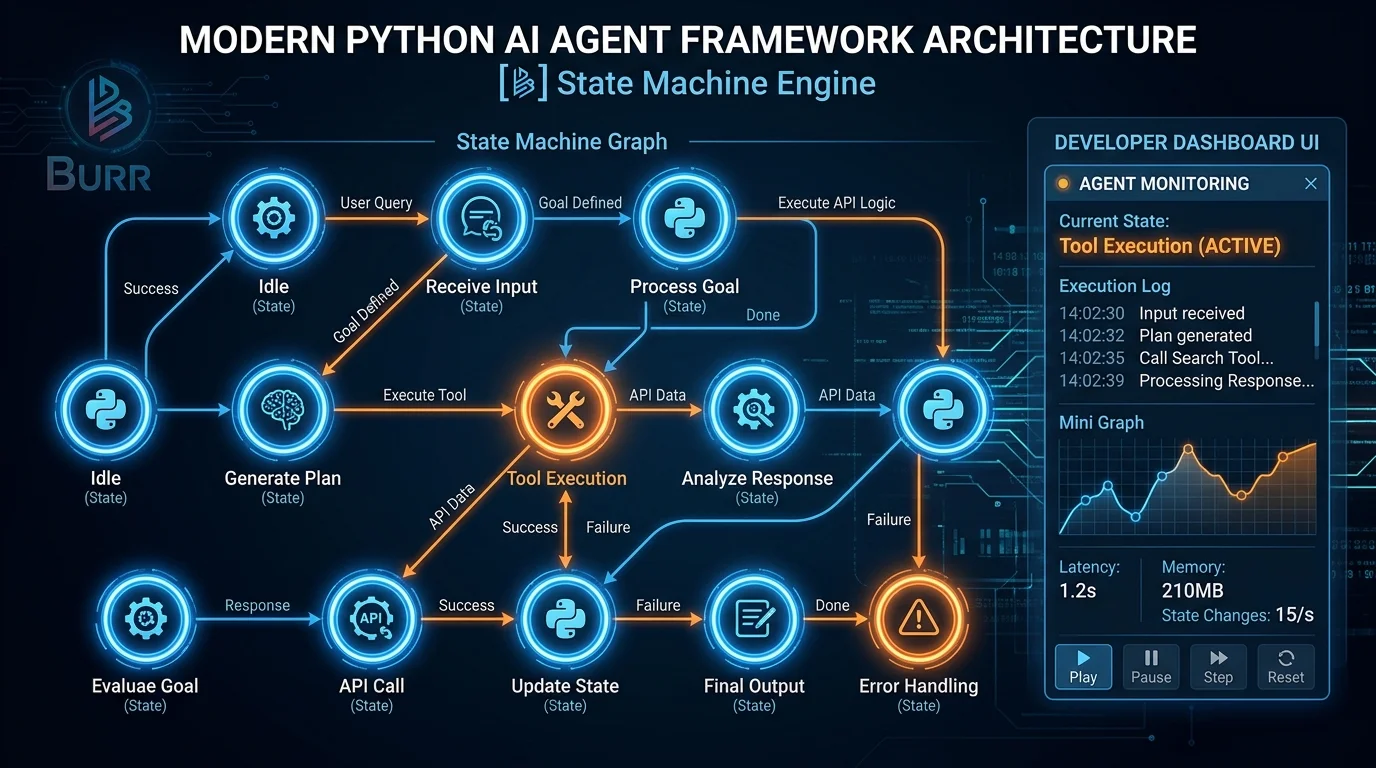
Что такое Apache Burr: архитектура за 5 минут
Burr — это лёгкий in-process Python-фреймворк, стандартизирующий выражение и выполнение конечных автоматов в виде графов, управляемых действиями (action-driven graphs), при этом делая выполнение графа легко наблюдаемым.
В основе Burr лежат три ключевые концепции:
- Action (Действие) — атомарный шаг приложения, декорированный Python-функцией
- State (Состояние) — неизменяемый (immutable) объект, передающийся между действиями
- Transition (Переход) — правило, определяющее порядок выполнения действий
Приложение описывается как набор actions и transitions — без DSL, без YAML, только Python-функции и декораторы.
Вот минимальный пример чат-бота на Burr:
from burr.core import action, State, ApplicationBuilder
@action(reads=["messages"], writes=["messages"])
def chat(state: State, llm_client) -> State:
response = llm_client.chat(state["messages"])
return state.update(
messages=[*state["messages"], response]
)
app = (
ApplicationBuilder()
.with_actions(chat)
.with_transitions(("chat", "chat"))
.with_state(messages=[])
.with_tracker("local") # сохранение трассировок локально
.build()
)
app.run(halt_after=["chat"], inputs={"llm_client": client})
Обратите внимание: фреймворк работает везде, где может запускаться Python-процесс. Никаких дополнительных серверов для ядра логики не нужно.
Три кита Burr: состояние, наблюдаемость, тестируемость
1. Управление состоянием (State Management)
Burr фокусируется на управлении состоянием и рабочих процессах, управляемых действиями, что делает его особенно актуальным для оркестрации AI-агентов, симуляций и систем принятия решений.
State в Burr — иммутабельный объект. Каждое действие получает состояние на вход и возвращает новое состояние на выход. Это устраняет целый класс ошибок, связанных с мутабельным глобальным состоянием.
Burr автоматически сохраняет состояние на диск, в базы данных или пользовательские бэкенды. Это означает: при сбое агента на шаге 7 вы можете перезапустить его именно с шага 7, а не с начала.
2. Встроенный UI для отладки
UI Burr позволяет мониторить, отлаживать и трассировать каждый шаг приложения в реальном времени — изменения состояния видны по мере их возникновения.
Burr включает UI для отслеживания/мониторинга/трассировки системы в реальном времени, а также подключаемые персистеры (например, для памяти) для сохранения и загрузки состояния приложения.
3. Тестируемость из коробки
Burr поощряет подход к тест-разработке, поскольку фреймворк направляет разработчиков структурировать код удобным для юнит- и интеграционного тестирования образом.
Каждое действие — чистая функция. Её можно протестировать изолированно, передав нужное состояние:
import pytest
from burr.core import State
def test_chat_action():
initial_state = State({"messages": [{"role": "user", "content": "Привет"}]})
mock_client = MockLLMClient(response="Привет! Чем могу помочь?")
result_state = chat(initial_state, llm_client=mock_client)
assert len(result_state["messages"]) == 2
assert result_state["messages"][-1] == "Привет! Чем могу помочь?"
Архитектура потока данных в Burr
graph TD
A[Пользовательский запрос] --> B[Action: preprocess]
B --> C{Переход}
C -->|нужен поиск| D[Action: retrieve_context]
C -->|простой вопрос| E[Action: chat]
D --> E
E --> F[State: обновлённые messages]
F --> G{Halt condition?}
G -->|нет| C
G -->|да| H[Ответ пользователю]
F -.->|персистенция| I[(База данных / Диск)]
F -.->|трассировка| J[Burr UI]
Граф явно описывает поток: нет скрытой магии, нет цепочек внутри цепочек. Разработчик в любой момент видит, в каком состоянии находится агент и почему он принял то или иное решение.
Apache Burr vs конкуренты: честное сравнение
Выбор фреймворка для AI-агентов — не просто технический вопрос, это вопрос архитектурной философии. Рассмотрим, чем Burr отличается от главных альтернатив.
| Критерий | Apache Burr | LangChain / LangGraph | LlamaIndex | CrewAI / AutoGen |
|---|---|---|---|---|
| Парадигма | State machine, action graph | Chain / Graph | Data-centric RAG | Role-based multi-agent |
| Кривая обучения | Низкая — чистый Python | Высокая — много абстракций | Средняя | Низкая для старта |
| Управление состоянием | Нативное, иммутабельное | Через LangGraph | Ограниченное | Ограниченное |
| Наблюдаемость | Встроенный UI + OpenTelemetry | LangSmith (платный) | Сторонние инструменты | Сторонние инструменты |
| Тестируемость | Высокая (чистые функции) | Средняя | Средняя | Низкая |
| Привязка к вендору | Нет | Экосистема LangChain | Экосистема LlamaIndex | Нет |
| Лицензия | Apache 2.0 | MIT | MIT | MIT |
| Зрелость | Incubating (2024) | Зрелый (2022) | Зрелый (2022) | Активно развивается |
«После оценки нескольких других запутанных LLM-фреймворков их элегантное и при этом комплексное решение управления состоянием оказалось именно тем ответом, который нам был нужен для запуска роботов на основе AI-решений.» — пользователь Apache Burr
По словам разработчиков, перешедших с LangChain на Burr, на старт с Burr ушло несколько часов — против дней и недель, потраченных на изучение LangChain.
Старший архитектор решений Provectus отмечает: по сравнению со многими агентными LLM-платформами (LangChain, CrewAI, AutoGen, Agency Swarm и др.) Burr предоставляет более надёжный фреймворк для проектирования сложных поведений.
Практический пример: мультиагентная система с Burr
Рассмотрим построение простой RAG-системы с двумя агентами — поисковым и генерирующим:
from burr.core import action, State, ApplicationBuilder, expr
@action(reads=["query"], writes=["context"])
def retrieve(state: State, vector_store) -> State:
"""Агент поиска: находит релевантный контекст"""
docs = vector_store.similarity_search(state["query"], k=3)
context = "\n".join([doc.page_content for doc in docs])
return state.update(context=context)
@action(reads=["query", "context"], writes=["answer", "done"])
def generate(state: State, llm) -> State:
"""Агент генерации: формирует ответ на основе контекста"""
prompt = f"Контекст: {state['context']}\n\nВопрос: {state['query']}"
answer = llm.invoke(prompt)
return state.update(answer=answer, done=True)
@action(reads=["done"], writes=[])
def end(state: State) -> State:
return state
app = (
ApplicationBuilder()
.with_actions(retrieve, generate, end)
.with_transitions(
("retrieve", "generate"),
("generate", "end", expr("done")),
)
.with_state(query="Как работает Burr?", context="", answer="", done=False)
.with_entrypoint("retrieve")
.with_tracker("local") # UI-трассировка
.build()
)
action_name, result_state, _ = app.run(halt_after=["end"])
print(result_state["answer"])
Опциональная система наблюдаемости может запускаться как отдельный процесс или через Docker и интегрируется с открытыми стандартами, такими как OpenTelemetry.
Чтобы запустить Burr UI локально, достаточно двух команд:
pip install burr[start]
burr
UI откроется на localhost:7241 с демо-данными и живым чат-ботом для тестирования.
Интеграции и экосистема
Burr интегрируется с инструментами и фреймворками, которые вы уже используете — без vendor lock-in и без обёрток.
Apache Burr хорошо работает с любыми приложениями, использующими LLM, и может интегрироваться с любыми предпочитаемыми фреймворками.
Ключевые интеграции:
- LLM-провайдеры: OpenAI, Anthropic, любые совместимые с OpenAI API
- Фреймворки: LangChain (LCEL), LlamaIndex, Apache Hamilton
- Инфраструктура: Ray, modal, FastAPI + EC2 и другие платформы для хостинга выполнения state machines
- Хранилища состояния: MySQL, S3 и другие технологии, позволяющие запускать Apache Burr поверх имеющейся инфраструктуры
- Наблюдаемость: OpenTelemetry, встроенный Burr UI
В планах — расширение поддержки выполнения на широком спектре платформ и облачных инфраструктур: Ray, Apache Airflow, AWS, GCP Vertex и других.
Для каких задач Burr подходит лучше всего
Фреймворк особенно хорошо подходит для рабочих процессов AI-агентов, симуляций и других динамических систем, и поставляется с самостоятельно размещаемым UI наблюдаемости, интегрированным с OpenTelemetry.
Вот сценарии, где Burr даёт наибольшую отдачу:
- Производственные AI-агенты — когда нужна отладка, воспроизведение ошибок и персистентность состояния
- Мультиагентные пайплайны — несколько специализированных агентов с явными переходами
- Симуляции и системы принятия решений — сложная условная логика с циклами
- RAG-приложения — когда важно трассировать каждый шаг поиска и генерации
- Команды, которым важна отладка — UI делает отладку простой, как никакой другой инструмент
Burr менее подходит, если вам нужна первичная работа с документами и продвинутый RAG — здесь LlamaIndex будет сильнее. Если нужна максимальная экосистема интеграций — смотрите на LangChain.
Заключение: почему Apache Burr заслуживает внимания
К марту 2025 года потребности в области данных, машинного обучения и генеративного AI резко возросли, однако по-прежнему не существует по-настоящему нейтрального к вендорам набора фреймворков, решающих эти задачи. Apache Burr претендует заполнить именно эту нишу.
Главный тезис прост: надёжный AI-агент — это прежде всего предсказуемый AI-агент. Burr достигает предсказуемости через три механизма:
- Иммутабельное состояние — нет скрытых мутаций, нет сюрпризов
- Явный граф переходов — каждое решение агента задокументировано кодом
- Встроенная наблюдаемость — UI и OpenTelemetry из коробки
Burr заполняет пробел, предоставляя лёгкий, Python-нативный фреймворк, стандартизирующий выражение высокоуровневых вычислительных графов и поставляемый с самостоятельно размещаемой наблюдаемостью, одновременно продвигая лучшие практики разработки ПО для ускорения итерационных циклов.
Если вы строите AI-агента, который должен работать в продакшене — а не только в демо — Apache Burr стоит добавить в список инструментов для оценки.