Глубокое обучение: обзор для любопытных
Полный обзор глубокого обучения: архитектуры нейросетей, обучение, CNN, RNN, Transformer — доступно и без воды.
Введение: когда машина обыгрывает чемпиона мира
В 2016 году программа AlphaGo сыграла серию партий против девятидановского профессионала Ли Седоля — одного из сильнейших игроков в го в истории — и выиграла со счётом 4:1. До этого го считался неподъёмной задачей для компьютеров: простые правила игры порождают экспоненциальное количество позиций на доске, несравнимо больше, чем в шахматах.
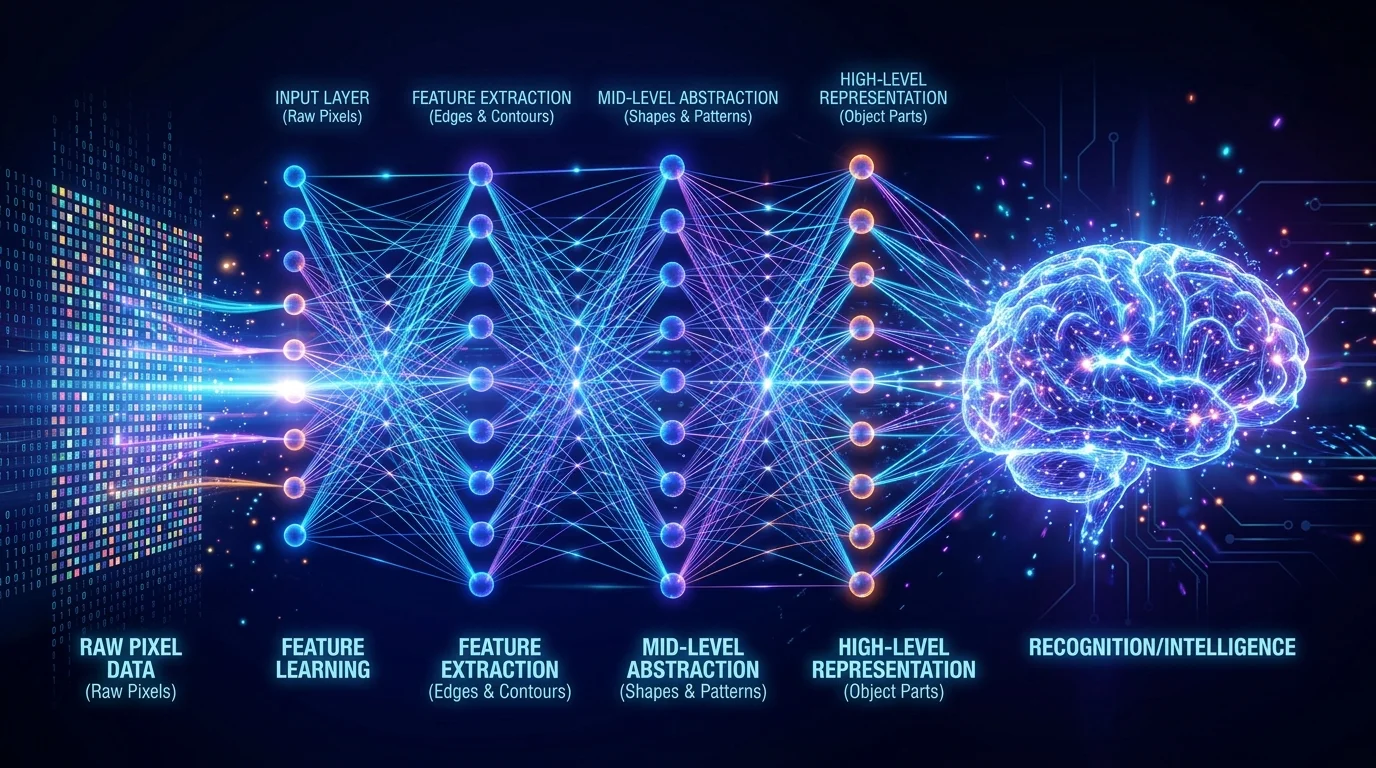
Что позволило машине достичь этого? Ответ — глубокое обучение (deep learning). Глубокие нейронные сети (DNN) — это класс моделей машинного обучения, вдохновлённых структурой человеческого мозга. Они состоят из множества слоёв взаимосвязанных нейронов, способных обнаруживать сложные паттерны в данных. DNN произвели революцию в распознавании изображений, обработке естественного языка и речи.
Эта статья — структурированный обзор ключевых идей глубокого обучения, основанный на знаменитой работе Лилиан Вэн «An Overview of Deep Learning for Curious People». Вэн ведёт технический блог Lil’Log с 2017 года — изначально как личный дневник заметок о машинном обучении, который со временем стал одним из самых авторитетных образовательных ресурсов в сообществе.
1. Что такое глубокое обучение и почему «глубокое»?
Машинное обучение — это набор техник, позволяющих компьютерам учиться на данных и опыте, а не следовать жёстко запрограммированным правилам. Глубокое обучение — подраздел ML, где «глубина» означает количество слоёв в нейронной сети.
«Мелкие» и «глубокие» обучающиеся системы различаются глубиной своих путей передачи сигнала ошибки — цепочек причинно-следственных связей между действиями и эффектами.
Shallow и deep learners различаются глубиной credit assignment paths — цепочек потенциально обучаемых причинно-следственных связей между действиями и результатами.
Практически это означает: чем больше слоёв, тем более абстрактные признаки способна извлекать сеть. Первые слои распознают края и текстуры, средние — формы и объекты, последние — семантические понятия.
Биологическая аналогия
Идея восходит к модели перцептрона Розенблатта (1958), вдохновлённой нейронами мозга. Современный искусственный нейрон:
- Принимает входные сигналы x₁, x₂, …, xₙ
- Взвешивает их: z = w₁x₁ + w₂x₂ + … + b
- Пропускает через функцию активации: a = f(z)
- Передаёт результат следующему слою
import numpy as np
def neuron(inputs, weights, bias, activation='relu'):
z = np.dot(weights, inputs) + bias
if activation == 'relu':
return np.maximum(0, z) # ReLU: f(z) = max(0, z)
elif activation == 'sigmoid':
return 1 / (1 + np.exp(-z))
return z
2. Ключевые концепции: от данных до весов
Обучение с учителем и обратное распространение ошибки
Матричное исчисление и градиентная оптимизация — критически важны для обучения и тонкой настройки нейронных сетей. Алгоритм backpropagation (обратное распространение ошибки) — сердце всего процесса обучения:
- Делаем прямой проход (forward pass): предсказываем выход
- Считаем ошибку (loss): насколько предсказание отличается от правды
- Делаем обратный проход (backward pass): вычисляем градиенты
- Обновляем веса: w ← w − η · ∇L
Многослойные feed-forward сети описываются через свою архитектуру, процесс обучения и алгоритм backpropagation.
Проблемы оптимизации
Ключевые сложности оптимизации нейронных сетей включают насыщение функций активации, затухание и взрыв градиентов, а также инициализацию весов.
Функции активации: сравнение
| Функция | Формула | Диапазон | Проблема |
|---|---|---|---|
| Sigmoid | 1/(1+e⁻ˣ) | (0, 1) | Затухание градиентов |
| Tanh | (eˣ−e⁻ˣ)/(eˣ+e⁻ˣ) | (−1, 1) | Затухание градиентов |
| ReLU | max(0, x) | [0, ∞) | «Мёртвые» нейроны |
| Leaky ReLU | max(0.01x, x) | (−∞, ∞) | — |
| GELU | x·Φ(x) | (−∞, ∞) | Сложнее вычислять |
3. Архитектуры: CNN, RNN и Transformer
Разные задачи требуют разных архитектур. Три парадигмы доминировали в истории deep learning.
graph TD
A[Входные данные] --> B{Тип данных?}
B -->|Изображения| C[CNN\nСвёрточные сети]
B -->|Последовательности| D[RNN / LSTM\nРекуррентные сети]
B -->|Текст / Мультимодаль| E[Transformer\nАттенция]
C --> F[Классификация\nДетекция объектов]
D --> G[Перевод\nГенерация текста]
E --> H[LLM: GPT, Gemini\nVision: ViT]
Свёрточные нейронные сети (CNN)
CNN идеальны для изображений. Вместо того чтобы соединять каждый нейрон с каждым пикселем, свёрточный слой применяет небольшие фильтры (kernels), скользящие по изображению. Это даёт:
- Трансляционная инвариантность: кот в углу = кот в центре
- Иерархия признаков: края → текстуры → части объекта → объект
- Экономия параметров: один фильтр для всего изображения
Архитектурная эволюция CNN: LeNet (1998) → AlexNet (2012) → VGG → ResNet → EfficientNet.
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(32 * 16 * 16, 10)
def forward(self, x):
x = self.pool(nn.functional.relu(self.conv1(x)))
x = x.view(-1, 32 * 16 * 16)
return self.fc(x)
Рекуррентные нейронные сети (RNN / LSTM)
Для последовательностей — текста, речи, временных рядов — нужна память о прошлом. RNN передаёт скрытое состояние h от шага к шагу. Проблема: затухание на длинных последовательностях.
LSTM (Long Short-Term Memory) решает это через механизм «ворот» (gates): forget gate, input gate, output gate. Сеть учится, что помнить, а что забывать.
Transformer: революция аттенции
Среди ключевых архитектур нейронных сетей выделяют Feedforward NN, Convolutional NN, Recurrent NN и Transformers.
Transformer (Vaswani et al., 2017) заменил рекуррентность механизмом Self-Attention: каждый токен может «смотреть» на все остальные токены сразу. Это дало:
- Параллельное обучение (в отличие от последовательного RNN)
- Захват дальних зависимостей в тексте
- Масштабируемость до миллиардов параметров
Именно Transformer лежит в основе GPT-4, Gemini, Claude и всех современных LLM.
4. Масштабирование и законы масштаба
Один из самых важных эмпирических результатов последних лет — законы масштаба (scaling laws).
Scaling laws — одно из наиболее критических эмпирических открытий в глубоком обучении. Суть проста: потери при обучении L предсказуемо снижаются по мере увеличения размера модели N, объёма данных D и вычислительных ресурсов C — по степенному закону.
Можно рассматривать законы масштаба как фреймворк для описания взаимосвязи между вычислениями, потерями, размером модели и данными — по сути, это вопрос об оптимальном распределении вычислительных ресурсов между N и D.
Почему «больше» работает?
Нейронные сети можно охарактеризовать объёмом вычислений и памяти, доступных в одном прямом проходе — и если оптимизировать их с помощью градиентного спуска, процесс оптимизации сам разберётся, как использовать эти ресурсы для организации вычислений и хранения информации.
5. Обучение без учителя, генеративные модели и агенты
Обучение без учителя
Помимо глубокого обучения с учителем (включая историю backpropagation), активно развиваются обучение без учителя, обучение с подкреплением и эволюционные методы.
Ключевые методы:
- Автоэнкодеры: сжимают данные в латентное пространство и восстанавливают их
- VAE (Variational Autoencoders): добавляют вероятностный смысл к латентному пространству
- GAN (Generative Adversarial Networks): генератор vs. дискриминатор в игре с нулевой суммой
- Диффузионные модели: постепенное «зашумление» и обучение обращать этот процесс
Обучение с подкреплением (RL)
RL лежит в основе AlphaGo, ChatGPT (RLHF) и роботики. AlphaGo победил лучшего человека в игре го. Расширенный алгоритм AlphaGo Zero затем победил AlphaGo со счётом 100:0 — без обучения с учителем на человеческих знаниях.
LLM-агенты: новый рубеж
Потенциал LLM выходит далеко за рамки генерации текстов: модель можно рассматривать как мощный универсальный решатель задач. В системе LLM-агентов языковая модель выступает «мозгом», дополненным ключевыми компонентами: планированием, памятью и инструментами.
- Модель генерирует несколько ответов на вопрос
- Люди-разметчики ранжируют ответы по качеству
- Обучается reward model, предсказывающая предпочтения
- PPO (алгоритм RL) оптимизирует языковую модель под reward model
- Результат: ответы, соответствующие ожиданиям человека
Заключение: почему глубокое обучение изменило всё
Нейронные сети и глубокое обучение стали центральными как для AI как академической дисциплины, так и для индустрии. За десятилетие прошли путь от игры в го до генерации кода, изображений, видео и решения задач, которые казались неподъёмными.
Ключевые выводы:
- Глубина = абстракция: чем больше слоёв, тем сложнее признаки
- Архитектура имеет значение: CNN для пространства, RNN для времени, Transformer для всего
- Масштаб работает: больше данных + больше параметров + больше вычислений → лучше результат
- RL замыкает петлю: от обучения с учителем к автономным агентам
Идея поразительна: не разрабатывать алгоритм решения задачи, а обучать модель, которая сама научится этому алгоритму. Именно в этом — магия и обещание глубокого обучения.
- Курс: MIT 6.S191 (бесплатно, YouTube)
- Книга: Deep Learning — Goodfellow, Bengio, Courville (бесплатно онлайн)
- Блог: Lil’Log — Lilian Weng (lilianweng.github.io)
- Практика: PyTorch tutorials + Kaggle соревнования
- Фреймворк: начните с PyTorch — он стал стандартом в исследованиях