Healthchecks.io переходит на self-hosted хранилище
Как Healthchecks.io отказался от облачного S3 в пользу Versity S3 Gateway на своём сервере — и что из этого вышло.
Когда небольшой, но критически важный SaaS-сервис отказывается от облачного хранилища в пользу самостоятельно поднятого S3-совместимого решения — это уже не просто техническое решение, а манифест. В апреле 2026 года автор и единственный разработчик Healthchecks.io Петерис Кауне (Pēteris Caune) опубликовал подробный пост о том, как и почему сервис переехал с управляемого облачного Object Storage на собственный сервер. История получилась поучительной для любого, кто строит production-инфраструктуру.
Что такое Healthchecks.io и зачем ему object storage
Healthchecks.io — это онлайн-сервис для мониторинга регулярно выполняемых задач, таких как cron-джобы. Он использует технику «Dead man’s switch»: отслеживаемая система должна «отмечаться» на Healthchecks.io через заданные интервалы времени, и когда сервис обнаруживает пропущенную отметку — отправляет оповещение.
Healthchecks.io — продукт компании SIA Monkey See Monkey Do, которую единолично возглавляет Петерис Кауне — давний Python-разработчик из Валмиеры, Латвия. То есть весь production ведёт один человек. И именно это обстоятельство станет ключевым в выборе инфраструктурного решения.
Ping-эндпоинты Healthchecks.io принимают HTTP-запросы методами HEAD, GET и POST. При использовании POST клиенты могут включать произвольную полезную нагрузку в тело запроса. Healthchecks.io хранит первые 100 КБ тела запроса: если тело маленькое — оно сохраняется в PostgreSQL, а если крупнее порога — в S3-совместимое объектное хранилище.
Размеры объектов варьируются от 100 байт до 100 000 байт, средний размер — 8 КБ. В среднем происходит 30 операций загрузки в секунду с регулярными пиками до 150 загрузок/сек. При этом идёт постоянная ротация загружаемых и удаляемых объектов.
История миграций: от OVHcloud к UpCloud и обратно к себе
Путь к self-hosted решению был постепенным. Сначала использовался OVHcloud Object Storage — европейский провайдер без поштучной оплаты запросов. Затем последовала смена на UpCloud.
В 2024 году произошла миграция на UpCloud — так же, как и OVHcloud, без платы за каждый запрос, европейская компания. Первоначально наблюдалось заметное улучшение качества: S3-операции выполнялись быстрее, серверных ошибок и таймаутов стало меньше.
Но идиллия длилась недолго:
Со временем производительность UpCloud object storage начала ухудшаться. Были периоды, когда все операции становились медленными и упирались в лимиты таймаутов. Операции S3 DeleteObjects, в частности, становились всё медленнее и медленнее.
В коде Healthchecks.io есть места, где S3-операции выполняются прямо в цикле HTTP-запрос/ответ. Если отдельные операции занимают несколько секунд — это может «задушить» процессы веб-сервера. При использовании UpCloud пришлось добавить логику сброса нагрузки, чтобы медленные S3-операции не перерастали в более серьёзные проблемы.
Латентность — это не просто цифра на графике. Когда S3 тормозит прямо в HTTP-цикле, это каскадом валит весь сервис.
Почему не Minio, SeaweedFS или Garage
Прежде чем остановиться на Versity, автор провёл эксперименты с тремя популярными self-hosted решениями:
Были проведены локальные эксперименты с Minio, SeaweedFS и Garage. Основным возражением против всех них была операционная сложность. Следовать инструкциям «для начала» и поднять базовый кластер — не так уж сложно. Но для production-ready setup потребовалось бы, как минимум, гораздо больше.
Поскольку проект ведётся командой из одного человека, при том что уже запущены self-hosted Postgres, self-hosted HAProxy load balancers и self-hosted email — добавлять ответственность за ещё одну нетривиальную систему крайне нежелательно.
Сравнение рассмотренных вариантов
| Решение | Тип | Операционная сложность | Per-request цены | EU-локация |
|---|---|---|---|---|
| AWS S3 | Managed | Низкая | Да (дорого) | Нет (CLOUD Act) |
| OVHcloud | Managed | Низкая | Нет | Да |
| UpCloud | Managed | Низкая | Нет | Да |
| Minio (кластер) | Self-hosted | Высокая | — | Сам выбираешь |
| SeaweedFS | Self-hosted | Высокая | — | Сам выбираешь |
| Garage | Self-hosted | Высокая | — | Сам выбираешь |
| Versity S3 Gateway | Self-hosted | Низкая | — | Сам выбираешь |
AWS S3 имеет поштучное ценообразование, что делало бы его дорогостоящим для паттернов использования Healthchecks.io (частые операции PutObject — по одной на каждый достаточно крупный ping-запрос). Кроме того, AWS подпадает под действие CLOUD Act, поэтому пришлось бы шифровать данные перед передачей в AWS, что добавило бы сложности.
Versity S3 Gateway: S3 поверх обычной файловой системы
Решением стал Versity S3 Gateway — малоизвестный, но элегантный инструмент:
Versity S3 Gateway превращает локальную файловую систему в S3-сервер. Операция S3 PutObject создаёт обычный файл на файловой системе, S3 GetObject читает обычный файл, а S3 DeleteObject удаляет файл. Никакой отдельной базы данных для хранения метаданных не требуется.
Это принципиально отличает его от Minio и прочих: никаких собственных форматов данных, никаких сложных кластерных протоколов.
# Обновление Versity S3 Gateway:
# 1. Остановить сервис
systemctl stop versity-s3
# 2. Заменить бинарник
cp versity-s3-new /usr/local/bin/versity-s3
# 3. Запустить снова
systemctl start versity-s3
Процедура обновления: заменить один бинарный файл и перезапустить systemd-сервис. Написан на Go и активно разрабатывается. Обнаруженный и сообщённый баг был исправлен всего за несколько дней.
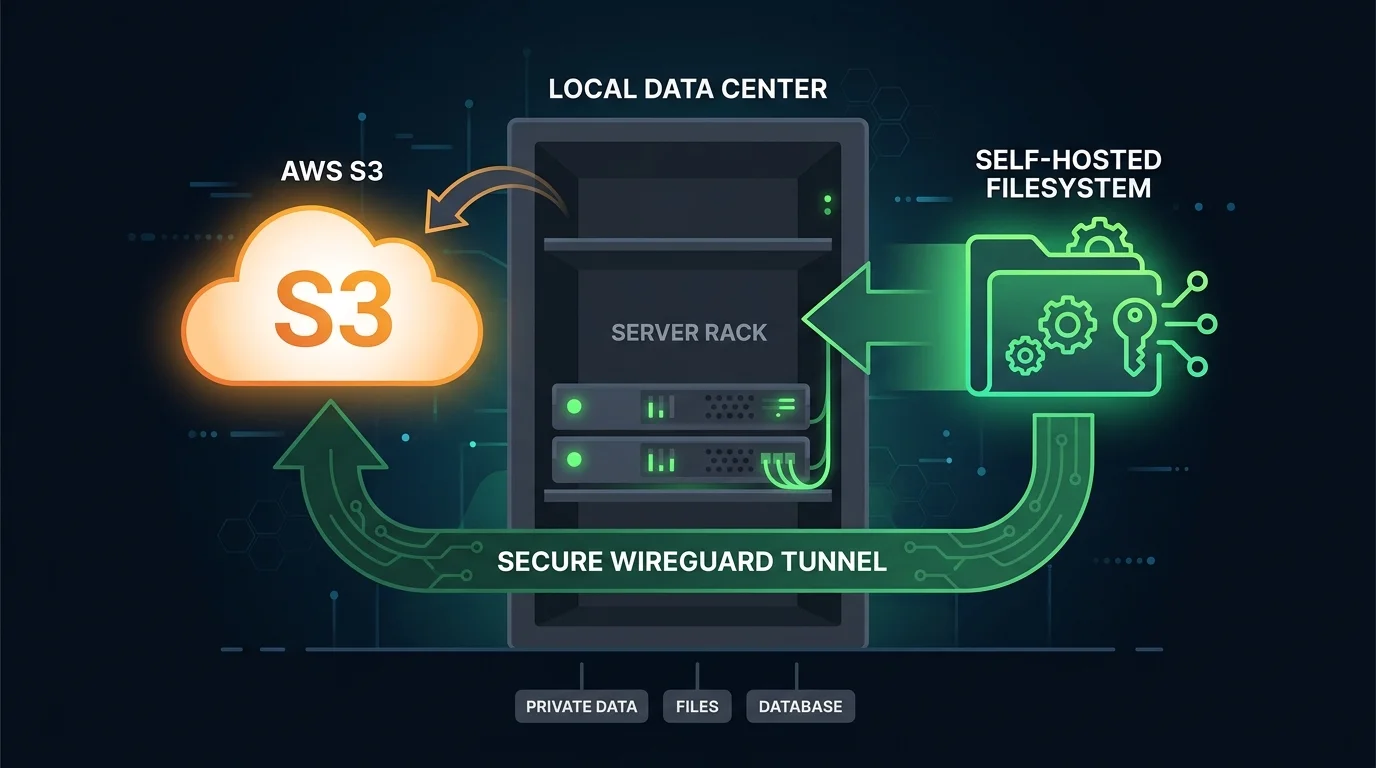
Архитектура развёртывания
graph TD
A["Клиент (cron, скрипт)"] -->|"HTTP ping"| B["Ping-эндпоинт\nhc-ping.com"]
B -->|"Тело запроса > порога"| C["Очередь загрузки"]
C -->|"S3 PutObject"| D["Versity S3 Gateway"]
D -->|"Файловые операции"| E["Btrfs RAID 1\n(2x NVMe)"]
E -->|"rsync каждые 2ч"| F["Backup сервер"]
F -->|"Ежедневно, шифрование"| G["Offsite backup\n(30 дней)"]
B -->|"Тело запроса < порога"| H["PostgreSQL"]
style D fill:#2d6a4f,color:#fff
style E fill:#1b4332,color:#fff
В марте 2026 года был выполнен переход на self-hosted object storage на базе Versity S3 Gateway. S3 API работает на выделенном сервере, слушает на приватном IP-адресе, а серверы приложений обращаются к нему через WireGuard-туннели. Объекты хранятся на локальных дисках сервера (два NVMe-диска в конфигурации RAID 1) на файловой системе Btrfs.
С Btrfs, в отличие от ext4, нет риска исчерпать иноды при хранении большого количества крошечных файлов. Это важно для паттерна Healthchecks.io, где средний объект весит всего 8 КБ — миллионы мелких файлов.
Резервное копирование
Каждые два часа rsync-процесс синхронизирует добавленные и удалённые файлы на backup-сервер. Ежедневно backup-сервер делает полную резервную копию, шифрует её и хранит off-site. Полные ежедневные бэкапы хранятся за последние 30 дней.
Если база данных недоступна — сервис полностью неработоспособен и алерты мониторинга перестают отправляться. Если недоступно объектное хранилище — пользователи не могут просматривать тела ping-запросов через веб-интерфейс или API, но система в остальном продолжает работать. Если часть тел ping-запросов будет безвозвратно потеряна — это плохо, но не так плохо, как потеря данных из PostgreSQL.
Результаты: что изменилось после перехода
После перехода на self-hosted object storage латентности S3-операций снизились, а очередь тел ping-запросов, ожидающих загрузки в хранилище, сократилась.
Список сторонних обработчиков данных (data sub-processors) стал на одну позицию короче. Это важно с точки зрения GDPR: меньше третьих сторон, которым передаются пользовательские данные.
Затраты выросли: аренда дополнительного выделенного сервера обходится дороже, чем хранение ~100 ГБ в управляемом объектном хранилище. Но улучшенная производительность и надёжность того стоят.
- Латентность S3-операций значительно снизилась
- Очередь загрузки ping-тел стала пустой
- GDPR: одним data sub-processor меньше
- Контроль: полный контроль над данными и инфраструктурой
- Стоимость: немного выросла, но предсказуема
Автор осторожно оптимистичен в отношении новой системы и считает её улучшением по сравнению с предыдущей. Но он открыт к очередной миграции, если найдётся система с лучшим соотношением компромиссов.
Уроки для инженеров: когда self-hosting оправдан
История Healthchecks.io даёт несколько важных практических уроков.
1. Managed ≠ надёжный. Деградация производительности UpCloud — не единичный случай. Управляемые хранилища оптимизируются под усреднённого клиента, и паттерны с высокочастотными мелкими объектами могут попасть в «слепое пятно» провайдера.
2. Операционная сложность — это реальная цена. Minio в production — это отдельная специализация. Versity S3 Gateway выигрывает не технической мощью, а простотой: файловая система как бэкенд, обновление одним бинарником.
3. Размер имеет значение. Всё ещё находясь в масштабе, где всё легко умещается на одной системе, а операции полного резервного копирования выполняются за разумное время — это большая удача. С терабайтными требованиями всё было бы значительно сложнее.
4. CLOUD Act — реальный риск для EU-сервисов. Отказ от AWS частично мотивирован юридическими рисками — данные европейских пользователей не должны попадать под американское законодательство.
5. Btrfs для мелких файлов — правильный выбор. В отличие от ext4 с его фиксированным числом инодов, Btrfs масштабируется для миллионов мелких объектов без риска исчерпания файловых дескрипторов.
Заключение
Миграция Healthchecks.io на Versity S3 Gateway — это не просто история об экономии или производительности. Это пример осознанного инженерного решения: выбрать простоту вместо функциональной полноты, взять под контроль критическую зависимость и честно оценить риски.
Для solo-разработчика или небольшой команды это может быть образцовый кейс: не гнаться за кластерными решениями там, где достаточно одного хорошо настроенного сервера с правильной файловой системой, RAID и регулярным rsync в бэкап.
«Я осторожно оптимистичен в отношении новой системы и открыт к очередной миграции, если найду систему с лучшим соотношением компромиссов.» — Pēteris Caune, Healthchecks.io
Подход «boring technology» в действии: PostgreSQL, rsync, Btrfs, WireGuard, systemd — ничего нового, но всё работает предсказуемо и понятно для одного человека. Именно в этом и состоит настоящая инженерная мудрость.