Как построить систему ответов на вопросы (ODQA)
Полный гайд по построению Open-Domain QA систем: архитектура Retriever-Reader, DPR, RAG, оценка качества и практические примеры кода.
Как построить систему ответов на вопросы открытого домена (ODQA)
Представьте: пользователь вводит вопрос «За что Эйнштейн получил Нобелевскую премию?» — и система мгновенно выдаёт точный ответ, не зная заранее, из какой статьи его брать. Именно это делают системы Open-Domain Question Answering (ODQA). Они не просто ищут по ключевым словам — они понимают вопрос, находят релевантный контекст в огромном корпусе текстов и извлекают конкретный фактический ответ.
С ростом популярности RAG-пайплайнов и LLM-ассистентов ODQA стала одной из самых востребованных архитектур в прикладном NLP. В этой статье разберём, как такие системы устроены изнутри, какие компоненты за что отвечают и как собрать работающий прототип с нуля.
Что такое ODQA и чем отличается от Reading Comprehension
Open-Domain Question Answering (ODQA) — это тип языковой задачи, в которой модель должна давать ответы на фактологические вопросы на естественном языке. Ключевое слово здесь — «открытый домен».
«Открытый домен» означает отсутствие заранее предоставленного релевантного контекста для любого произвольного фактического вопроса. Модель принимает на вход только вопрос — без сопроводительной статьи, где мог бы содержаться ответ.
Это принципиально отличает ODQA от задачи Reading Comprehension (RC): когда и вопрос, и контекст предоставляются одновременно — задача называется Reading Comprehension.
ODQA-модель может работать как с доступом к внешнему источнику знаний (например, Википедии), так и без него — эти два режима называются «open-book» и «closed-book» соответственно.
Модель, способная отвечать на любые вопросы относительно фактических знаний, открывает путь ко многим полезным приложениям — от чат-ботов до AI-ассистентов.
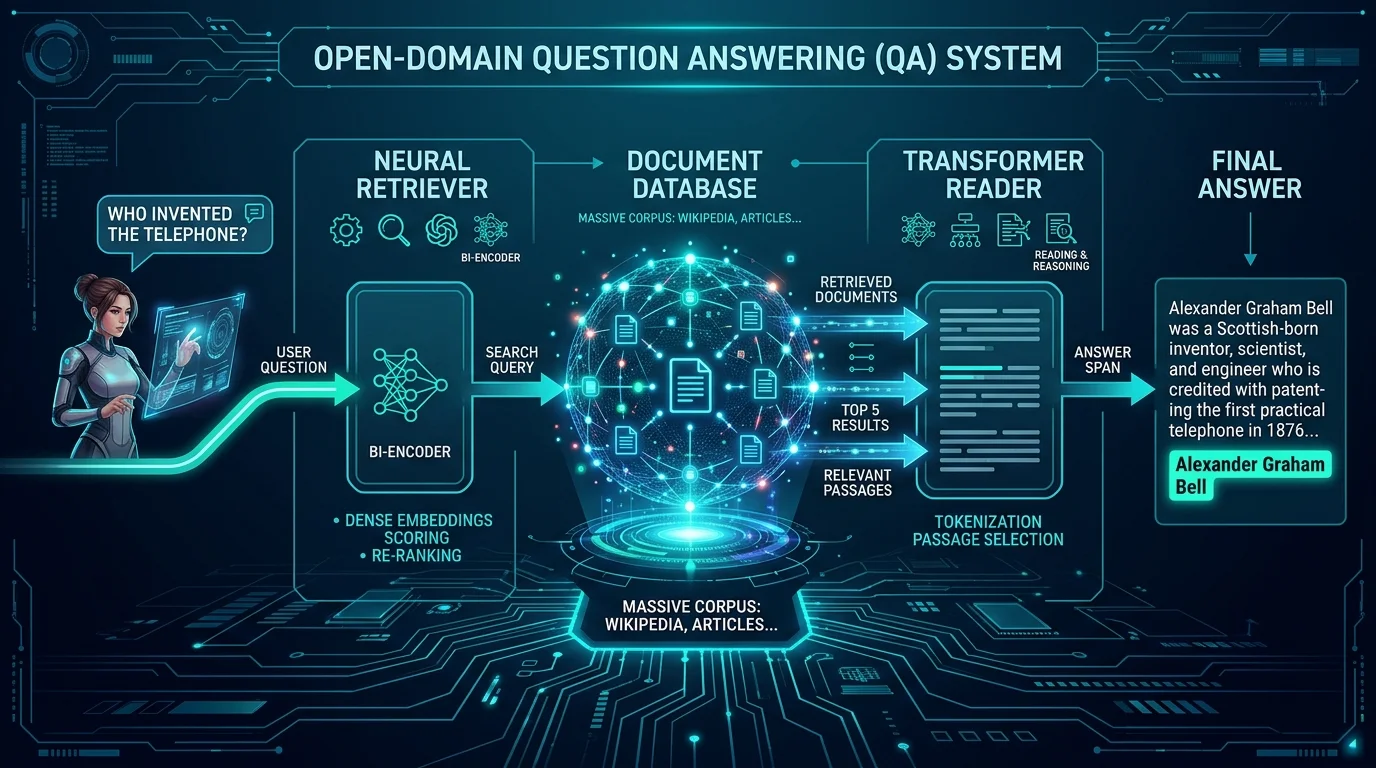
Архитектура: Retriever + Reader
Самый популярный и проверенный подход к ODQA — двухступенчатый пайплайн Retriever → Reader.
Процесс поиска ответа на вопрос можно разложить на два этапа: найти релевантный контекст во внешнем репозитории знаний; обработать извлечённый контекст для получения ответа.
Фреймворк Retriever-Reader объединяет информационный поиск с машинным пониманием текста. Впервые такой подход был предложен в DrQA («Document Retriever Question-Answering» от Chen et al., 2017).
graph LR
Q["Вопрос пользователя"] --> R["Retriever\n(поисковый модуль)"]
R --> KB[("База знаний\nWikipedia / документы")]
KB --> R
R --> TOP["Top-K релевантных\nпассажей"]
TOP --> RD["Reader\n(модель чтения)"]
RD --> A["Точный ответ"]
Retriever: как найти правильные документы
ODQA опирается на три компонента: векторную базу данных для хранения закодированных представлений данных, ретривер для кодирования контекста и вопроса, и модель-ридер, которая обрабатывает релевантные контексты и извлекает конкретный ответ.
Ретривер делится на два типа: разреженный (sparse) и плотный (dense). Методы разреженного поиска основаны на сопоставлении слов. К ним относятся Boolean Retrieval, BM25, SPLADE и UniCOIL.
В отличие от них, методы плотного поиска кодируют вопросы и пассажи в эмбеддинги, что позволяет выполнять семантическое сопоставление.
Sparse Retrieval (BM25/TF-IDF):
- Быстрый, не требует обучения
- Работает по точному совпадению слов
- Плохо справляется с перефразированием и синонимами
Dense Retrieval (DPR и аналоги):
Dense Passage Retrieval (DPR) — это первый шаг в парадигме RAG для улучшения производительности LLM. DPR дообучает предобученные сети для улучшения выравнивания эмбеддингов между запросами и релевантными текстовыми данными.
DPR-метод от Karpukhin et al. (2020) продемонстрировал, что обученные плотные представления способны существенно превзойти традиционные методы разреженного поиска, такие как BM25, — на 9–19% по точности поиска top-20 пассажей.
from transformers import DPRQuestionEncoder, DPRContextEncoder, DPRTokenizer
import torch
import faiss
import numpy as np
# Инициализация энкодеров
q_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
c_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
tokenizer = DPRTokenizer.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
# Кодирование вопроса
def encode_query(question: str) -> np.ndarray:
inputs = tokenizer(question, return_tensors="pt", truncation=True, max_length=64)
with torch.no_grad():
embeddings = q_encoder(**inputs).pooler_output
return embeddings.numpy()
# Поиск в FAISS-индексе
def retrieve_top_k(query_emb: np.ndarray, index: faiss.Index, k: int = 5):
distances, indices = index.search(query_emb, k)
return indices[0] # индексы найденных пассажей
Reader: как извлечь ответ из контекста
Ридер — это финальный этап в ODQA-пайплайне: он принимает контексты, возвращённые векторной базой данных и ретривером, и читает их для извлечения ответа.
Это называется «extractive QA», потому что модели не генерируют ответ — ответ уже существует, но скрыт где-то в тысячах или миллионах источников данных. Такой подход позволяет более интеллектуально и эффективно извлекать информацию из огромных хранилищ данных.
Типичный ридер на базе BERT определяет start_position и end_position — индексы начала и конца ответа в тексте пассажа:
from transformers import pipeline
# Ридер на базе BERT/RoBERTa
reader = pipeline(
"question-answering",
model="deepset/roberta-base-squad2"
)
def extract_answer(question: str, contexts: list[str]) -> dict:
best_answer = None
best_score = -float("inf")
for ctx in contexts:
result = reader(question=question, context=ctx)
if result["score"] > best_score:
best_score = result["score"]
best_answer = result
return best_answer
# Пример
answer = extract_answer(
question="За что Эйнштейн получил Нобелевскую премию?",
contexts=["Альберт Эйнштейн получил Нобелевскую премию 1921 года за открытие закона фотоэлектрического эффекта."]
)
print(answer["answer"]) # => "закон фотоэлектрического эффекта"
RAG: от Retriever-Reader к генеративным моделям
Классическая схема Retriever+Reader хорошо работает для извлечения точных фрагментов текста, но в 2020 году появилась более гибкая парадигма — Retrieval-Augmented Generation (RAG).
RAG объединяет предобученные языковые модели с внешними текстовыми базами для получения более информированных и контекстуально релевантных ответов, значительно улучшая задачи вроде QA и диалоговых AI. Архитектура RAG интегрирует механизмы плотного поиска и трансформерные генеративные модели, позволяя извлекать релевантные документы и использовать их как условие для точных ответов.
RAG решает ключевую проблему LLM: вставляет внешние документы в промпт, обновляя знания модели без дообучения.
Используйте RAG, если:
- Ответ требует перефразирования или синтеза из нескольких источников
- База знаний часто обновляется
- Нужен более «человекообразный» стиль ответа
Используйте классический Extractive Reader, если:
- Нужна точная цитата из документа
- Важна минимальная латентность
- Требуется высокая предсказуемость ответов
Сравнение подходов
| Параметр | Sparse Retrieval (BM25) | Dense Retrieval (DPR) | RAG (DPR + Generator) |
|---|---|---|---|
| Обучение | Не требуется | Требуется | Требуется |
| Семантический поиск | ❌ | ✅ | ✅ |
| Генерация ответа | Extractive | Extractive | Generative |
| Точность на NQ | ~41% EM | ~41.5% EM | ~44.5% EM |
| Скорость поиска | Очень высокая | Высокая (FAISS) | Высокая (FAISS) |
| Актуальность знаний | Зависит от индекса | Зависит от индекса | Зависит от индекса |
| Сложность деплоя | Низкая | Средняя | Высокая |
Архитектура выбирается под задачу: для поддержки клиентов с чёткими FAQ подойдёт BM25 + Extractive Reader; для сложного аналитического ассистента — DPR + RAG.
Метрики оценки качества ODQA
Прежде чем запускать систему в продакшн, нужно понять, как измерять её качество.
Бенчмаркинг OpenQA опирается на датасеты от общих (Natural Questions, TriviaQA, SQuAD-Open) до специализированных (COVID-QA, MedQA, ArchivalQA) и многоязычных (SQuAD-TR, XQuAD-TR).
Основные метрики включают Exact Match (EM), F1 (пересечение токенов), Retrieval Recall (R@k) и Passage MRR.
| Метрика | Что измеряет | Уровень |
|---|---|---|
| Exact Match (EM) | Точное совпадение с эталоном | Reader |
| Token F1 | Пересечение токенов с эталоном | Reader |
| Recall@K | Доля вопросов, где правильный пассаж попал в top-K | Retriever |
| MRR | Mean Reciprocal Rank — позиция первого правильного результата | Retriever |
Чтобы RAG работал эффективно, базовая модель поиска должна отлично справляться с поиском точной и релевантной информации. Обычно оценка модели проводится по метрикам top-5, top-20, top-50 и top-100 извлечённых пассажей. Исследования показывают, что LLM в основном используют информацию из top-1 до top-5 пассажей — что подчёркивает важность не только высокого recall, но и точности ранжирования.
Практический пайплайн: собираем ODQA с нуля
Вот минимальный рабочий пример полного ODQA-пайплайна с использованием haystack — одного из самых популярных фреймворков для построения таких систем:
from haystack import Pipeline
from haystack.document_stores import FAISSDocumentStore
from haystack.nodes import DensePassageRetriever, FARMReader
# 1. Инициализация хранилища с FAISS-индексом
document_store = FAISSDocumentStore(
faiss_index_factory_str="Flat",
embedding_dim=768
)
# 2. Загрузка документов
docs = [
{"content": "Альберт Эйнштейн получил Нобелевскую премию 1921 года за закон фотоэлектрического эффекта."},
{"content": "Мария Кюри дважды получила Нобелевскую премию: по физике (1903) и по химии (1911)."},
# ... тысячи документов
]
document_store.write_documents(docs)
# 3. Retriever — Dense Passage Retrieval
retriever = DensePassageRetriever(
document_store=document_store,
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
use_gpu=True
)
document_store.update_embeddings(retriever)
# 4. Reader — BERT-based QA
reader = FARMReader(
model_name_or_path="deepset/roberta-base-squad2",
use_gpu=True
)
# 5. Сборка пайплайна
pipeline = Pipeline()
pipeline.add_node(component=retriever, name="Retriever", inputs=["Query"])
pipeline.add_node(component=reader, name="Reader", inputs=["Retriever"])
# 6. Запрос
result = pipeline.run(
query="За что Эйнштейн получил Нобелевскую премию?",
params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 3}}
)
print(result["answers"][0].answer)
# => "закон фотоэлектрического эффекта"
Если haystack кажется избыточным:
- LangChain + FAISS/Chroma — гибко, много коннекторов
- LlamaIndex — отличен для RAG поверх собственных документов
- txtai — лёгкий фреймворк с встроенным semantic search
- Hugging Face Pipelines — если нужен минимальный код
Современные тренды и открытые вызовы
Трендом является многоуровневая архитектура: генеративное дополнение, гибридный поиск и глубокое слияние ответов формируют ODQA-пайплайны, где генерация, поиск, переранжирование и рассуждение объединяются в тесно связанный, сквозной оптимизируемый фреймворк.
Перспективным направлением является Query Augmentation — дополнение запроса перед поиском. Хотя zero-shot Chain-of-Thought (CoT) хорошо работает на арифметических задачах, его применение к ODQA изучено меньше. Однако дополнение вопроса шагами рассуждения CoT повышает способность к поиску и улучшает результаты на ODQA.
Среди открытых вызовов — развёртывание на ограниченном оборудовании (мобильные устройства, edge), требующее кардинального улучшения размера индекса и модели.
Задачи ODQA всё активнее используются для тестирования RAG-систем с поколением, дополненным поиском.
Заключение
Open-Domain Question Answering — это не один алгоритм, а целый стек взаимодействующих компонентов. Ключевые выводы:
- Retriever определяет потолок качества системы: если нужный пассаж не найден — Reader бессилен. Вкладывайте усилия в оценку и улучшение Recall@K.
- Sparse (BM25) vs Dense (DPR): начинайте с BM25 как бейзлайна, переходите к DPR когда нужен семантический поиск.
- RAG расширяет классическую схему генеративным ридером — это лучший выбор для гибких, человекообразных ответов.
- Метрики важны на каждом уровне: EM/F1 для Reader, Recall@K и MRR — для Retriever.
- Фреймворки (Haystack, LangChain, LlamaIndex) значительно ускоряют разработку — не изобретайте велосипед.
С появлением мощных LLM (GPT-4, Claude, Gemini) граница между open-book и closed-book QA размывается, но архитектура Retriever+Reader остаётся золотым стандартом для систем, где важна проверяемость, актуальность и контроль над источниками — будь то корпоративный ассистент, медицинский чат-бот или юридический поиск.