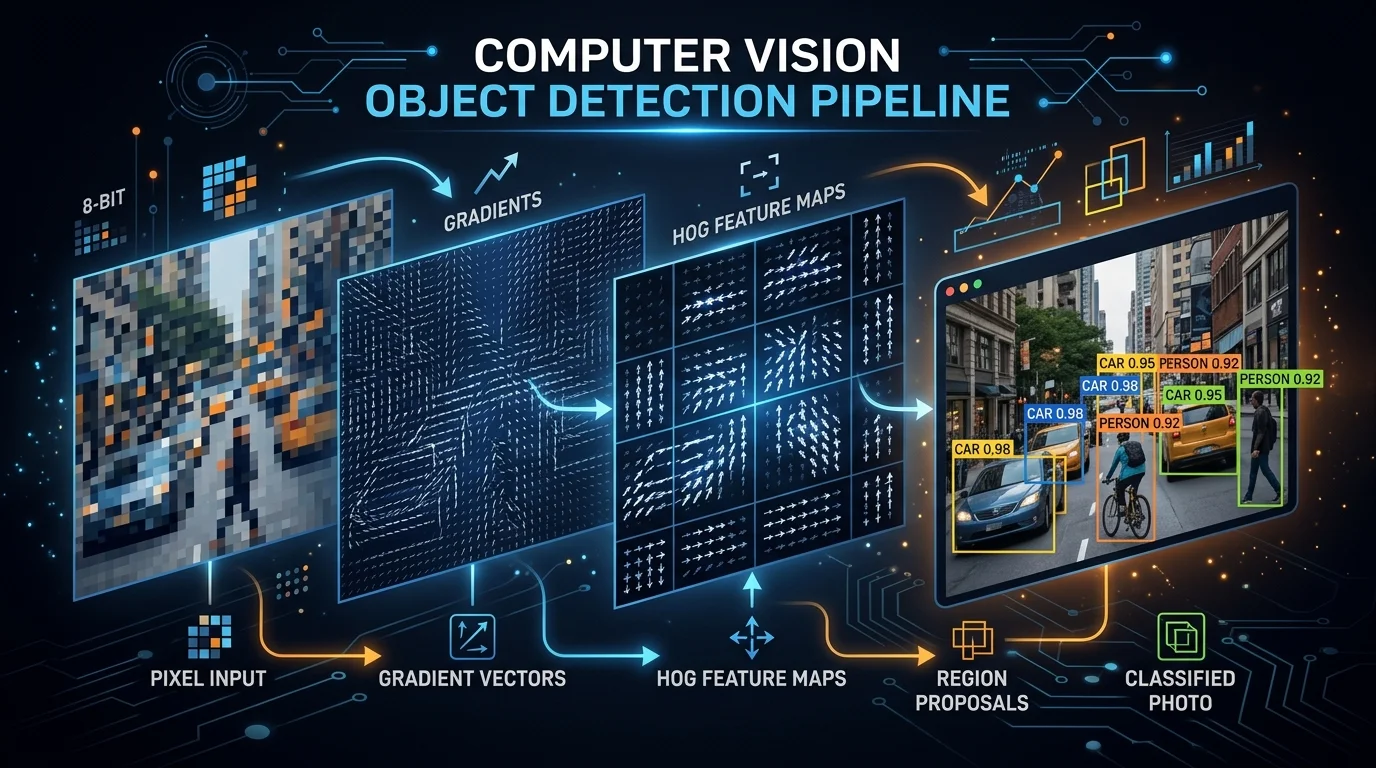
Object Detection для чайников: Gradient Vector, HOG и Selective Search
Разбираем основы компьютерного зрения: градиентные векторы, алгоритм HOG и Selective Search — фундамент современного детектирования объектов.
Введение: как машина «видит» объекты?
Как автономный автомобиль отличает знак «стоп» от пешехода в красной шапке? Как система видеонаблюдения за доли секунды находит лицо в толпе? За всем этим стоит область, которую называют детектированием объектов (object detection).
Важно сразу разграничить понятия: распознавание объектов (object recognition) — это определение того, присутствует ли объект на изображении, тогда как детектирование объектов (object detection) — это ещё и указание на то, где именно он находится.
Серия «Object Detection for Dummies» охватывает: (1) концепцию градиентного вектора изображения и то, как алгоритм HOG обобщает информацию по всем градиентным векторам; (2) как алгоритм сегментации изображения выделяет регионы, потенциально содержащие объекты; (3) как алгоритм Selective Search уточняет результаты сегментации для улучшения предложений регионов.
В этой статье мы пройдём тот же путь — от самых азов обработки изображений до интеллектуального поиска областей интереса. Никаких нейросетей пока — только математика и геометрия пикселей.
Что такое градиентный вектор изображения?
Прежде чем машина сможет «увидеть» объект, ей нужно понять структуру изображения. Ключевой инструмент для этого — градиентный вектор.
Градиенты представляют изменения интенсивности пикселей, давая ценную информацию о границах, контурах и вариациях формы объектов.
Градиенты определяют силу (магнитуду) и направление (ориентацию) границ в конкретной точке. При этом направление границы перпендикулярно направлению вектора градиента в точке вычисления.
Для каждого пикселя вычисляются частные производные по осям X и Y с помощью операторов свёртки (например, оператора Собела). На основе двух полученных значений строится вектор:
import numpy as np
from scipy import ndimage
def compute_gradients(image):
# Горизонтальное и вертикальное ядра Собела
Kx = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]])
Ky = np.array([[1, 2, 1], [0, 0, 0], [-1, -2, -1]])
Ix = ndimage.convolve(image.astype(float), Kx)
Iy = ndimage.convolve(image.astype(float), Ky)
# Магнитуда и угол градиента
magnitude = np.sqrt(Ix**2 + Iy**2)
angle = np.arctan2(Iy, Ix) * (180 / np.pi)
return magnitude, angle
Для каждого пикселя мы получаем два значения: магнитуду и ориентацию. Чтобы объединить эту информацию во что-то осмысленное, используют гистограмму — она помогает организовать и интерпретировать эти значения эффективно.
HOG: гистограмма ориентированных градиентов
Что такое HOG и зачем он нужен
Histogram of Oriented Gradients (HOG) — это дескриптор признаков, широко применяемый в компьютерном зрении для представления формы объекта путём кодирования интенсивности градиентов и их ориентаций в локальных областях изображения.
Алгоритм был предложен Навнитом Далалом и Биллом Триггсом в 2005 году для улучшения детектирования объектов — основной мотивацией послужило обнаружение пешеходов.
«HOG — это не просто алгоритм, это способ перевести визуальную форму объекта в язык чисел, понятный машине.»
HOG является дескриптором признаков в компьютерном зрении и обработке изображений для детектирования объектов. Он захватывает структуру или форму объекта, анализируя распределение (гистограммы) ориентаций градиентов в локальных частях изображения.
Пошаговая работа алгоритма HOG
flowchart TD
A[🖼️ Входное изображение] --> B[Предобработка: изменение размера\nдо стандарта 64×128 px]
B --> C[Вычисление градиентов\nпо осям X и Y]
C --> D[Разбивка на ячейки\n8×8 пикселей]
D --> E[Построение гистограммы\n9 бинов по 20°]
E --> F[Объединение ячеек в блоки\n2×2 ячейки = 16×16 px]
F --> G[Нормализация блоков\nпо яркости]
G --> H[📊 Итоговый вектор признаков HOG]
Шаг 1: Предобработка. Изображение переводится в оттенки серого и приводится к стандартному размеру, например 32×64 или 64×128 пикселей, чтобы обеспечить согласованность анализа.
Шаг 2: Разбивка на ячейки и вычисление гистограмм. Алгоритм HOG подсчитывает вхождения ориентаций градиентов в локализованных частях изображения. Он делит изображение на небольшие связные области — ячейки, и для пикселей внутри каждой ячейки вычисляет градиент изображения по осям X и Y.
Создаётся гистограмма градиентов в ячейках 8×8, содержащих 64 значения, распределённых по бинам гистограммы — квантизованным в 9 бинов по 20 градусов каждый (диапазон от 0° до 180°).
Каждый бин соответствует направлению градиента: 9 бинов по 20° для диапазона 0–180°. Это позволяет алгоритму HOG сжать 64 вектора всего до 9 значений.
Шаг 3: Нормализация блоков. Метод делит изображение на сетки ячеек, вычисляет магнитуду и направление градиента для каждого пикселя и агрегирует эти значения в гистограммы ориентаций для каждой ячейки. Эти гистограммы нормализуются по более крупным блокам для обеспечения инвариантности к изменениям освещённости и контраста.
Сравнение HOG с другими дескрипторами
| Дескриптор | Инвариантность к масштабу | Инвариантность к вращению | Скорость | Применение |
|---|---|---|---|---|
| HOG | Низкая | Низкая | Высокая | Пешеходы, тела |
| SIFT | Высокая | Высокая | Средняя | Ключевые точки |
| SURF | Высокая | Средняя | Средняя | Схожие сцены |
| ORB | Средняя | Средняя | Очень высокая | Real-time задачи |
Несмотря на свои ограничения, HOG остаётся фундаментальной техникой в компьютерном зрении, особенно в сочетании с классификаторами машинного обучения и в составе более сложных моделей.
HOG показывает хорошие результаты в детектировании объектов, однако оказывается чувствительным к повороту изображения, что ограничивает область его применения.
Пример: использование HOG с scikit-image
Существует множество готовых библиотек с реализацией алгоритма HOG, таких как OpenCV, SimpleCV и scikit-image.
from skimage.feature import hog
from skimage import data, color, transform
import matplotlib.pyplot as plt
# Загрузка тестового изображения
image = color.rgb2gray(data.astronaut())
image_resized = transform.resize(image, (128, 64))
# Вычисление HOG-дескриптора
fd, hog_image = hog(
image_resized,
orientations=9, # 9 бинов
pixels_per_cell=(8, 8), # ячейка 8×8
cells_per_block=(2, 2), # блок 2×2 ячейки
visualize=True
)
print(f"Размер HOG-вектора: {fd.shape}") # → (1764,)
fig, axes = plt.subplots(1, 2)
axes[0].imshow(image_resized, cmap='gray')
axes[0].set_title('Исходное изображение')
axes[1].imshow(hog_image, cmap='gray')
axes[1].set_title('HOG-визуализация')
plt.show()
Сегментация изображений: алгоритм Felzenszwalb–Huttenlocher
HOG описывает признаки на уже известном участке. Но как найти эти участки? Здесь вступает в игру сегментация изображений.
Когда на одном изображении присутствует несколько объектов (что верно почти для каждой реальной фотографии), необходимо выделить область, потенциально содержащую целевой объект, чтобы классификация выполнялась эффективнее.
Felzenszwalb и Huttenlocher (2004) предложили алгоритм сегментации изображения на схожие регионы с использованием графового подхода. Он также служит методом инициализации для Selective Search — популярного алгоритма предложения регионов.
Как работает графовая сегментация
Входное изображение представляется в виде неориентированного графа G=(V, E). Каждая вершина v_i ∈ V соответствует одному пикселю. Ребро e=(v_i, v_j) ∈ E соединяет две вершины. Связанный с ним вес w(v_i, v_j) измеряет несходство между пикселями по таким признакам, как цвет, местоположение, интенсивность. Чем выше вес, тем менее похожи два пикселя.
Алгоритм производит начальную сверхсегментацию (over-segmentation): изображение разбивается на много мелких однородных участков. Пороговый параметр k регулирует «зернистость» сегментации — чем больше k, тем крупнее получаемые сегменты.
Selective Search: умный поиск объектов
Идея и мотивация
Selective Search — это алгоритм предложения регионов для детектирования объектов, сочетающий достоинства полного перебора и сегментации. Он разработан для быстрой работы с очень высоким показателем полноты (recall).
В отличие от традиционных методов, рассматривающих тысячи случайных регионов, Selective Search фокусируется на тех частях изображения, которые имеют более высокую вероятность образовывать осмысленные конфигурации, делая алгоритм одновременно эффективным и мощным.
Алгоритм Selective Search: шаг за шагом
flowchart LR
A[🖼️ Исходное\nизображение] --> B[Сверхсегментация\nFelzenszwalb-Huttenlocher]
B --> C[Начальный набор\nмелких регионов]
C --> D{Жадный алгоритм:\nвыбрать 2 наиболее\nпохожих региона}
D --> E[Объединить\nв 1 регион]
E --> F[Добавить bounding box\nв список предложений]
F --> D
D --> G[🏁 Всё изображение —\nодин регион]
F --> G
Selective Search начинает с сегментации изображения на множество мелких регионов с помощью алгоритма Felzenszwalb.
Затем применяется иерархическая группировка: алгоритм начинает с начальных мелких регионов и последовательно объединяет регионы, схожие по цвету, текстуре, размеру и совместимости форм.
Для объединения похожих регионов используется жадный алгоритм. Он итеративно выбирает два наиболее похожих региона и сливает их:
- Из набора регионов выбираем два наиболее похожих
- Объединяем их в один, более крупный регион
- Повторяем, пока всё изображение не станет единым регионом
Метрики сходства в Selective Search
Selective Search использует 4 метрики сходства, основанные на цвете, текстуре, размере и совместимости форм. Для цветового сходства вычисляется цветовая гистограмма с 25 бинами для каждого канала, объединённая в 75-мерный дескриптор (25×3).
| Метрика | Что измеряет | Зачем нужна |
|---|---|---|
| Цвет | Гистограммы цветовых каналов | Объединять регионы одного цвета |
| Текстура | Гистограммы градиентов | Объединять регионы с похожей поверхностью |
| Размер | Относительная площадь регионов | Предотвращать поглощение мелких регионов |
| Форма | Совместимость bounding box | Заполнять «пробелы» между регионами |
Настраивая пороговый параметр k в алгоритме Felzenszwalb–Huttenlocher, меняя цветовое пространство и выбирая различные комбинации метрик сходства, можно генерировать разнообразные стратегии Selective Search. Версия, дающая предложения регионов наилучшего качества, использует смесь различных начальных сегментаций, сочетание нескольких цветовых пространств и объединение всех метрик сходства.
Связь с R-CNN
В архитектуре R-CNN Selective Search используется для выделения управляемого числа кандидатов ограничивающих рамок («region of interest», RoI), после чего CNN-признаки извлекаются из каждого региона независимо.
Selective Search — алгоритм предложения регионов, широко применяемый в двухэтапных архитектурах детектирования объектов, таких как R-CNN (Region-based Convolutional Neural Networks).
Практический пример: пайплайн от пикселей до кандидатов
Соберём всё воедино в Python-псевдокоде, показывающем классический пайплайн:
import cv2
import numpy as np
from skimage.feature import hog
def classic_detection_pipeline(image_path):
"""
Классический пайплайн детектирования объектов:
1. Вычисление градиентов
2. Извлечение HOG-признаков
3. Selective Search для region proposals
"""
# Шаг 1: Загрузка изображения
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Шаг 2: HOG-дескриптор для всего изображения
hog_features, _ = hog(
gray,
orientations=9,
pixels_per_cell=(8, 8),
cells_per_block=(2, 2),
visualize=True
)
# Шаг 3: Selective Search через OpenCV
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
ss.setBaseImage(img)
ss.switchToSelectiveSearchFast() # или Fast-режим
rects = ss.process() # Получаем ~2000 предложений регионов
print(f"HOG-вектор: {hog_features.shape}")
print(f"Предложено регионов: {len(rects)}")
# Шаг 4: Классификация каждого региона (SVM/CNN)
# ... здесь идёт классификатор ...
return rects
scikit-image, opencv-contrib-python (для Selective Search). Установите их командой: pip install scikit-image opencv-contrib-pythonЗаключение: фундамент, без которого нет современных детекторов
Мы прошли путь от математики отдельного пикселя до умного алгоритма поиска объектов:
- Градиентный вектор — основа: он кодирует информацию о границах и формах через магнитуду и ориентацию изменений яркости.
- HOG — агрегирует градиенты по ячейкам и блокам, превращая участок изображения в компактный числовой вектор, описывающий форму.
- Сегментация Felzenszwalb–Huttenlocher — разбивает изображение на однородные регионы с помощью графового подхода.
- Selective Search — иерархически объединяет сегменты, генерируя кандидатов на местоположение объектов для последующей классификации.
Серия «Object Detection for Dummies» начинается именно с базовых концепций обработки изображений — градиентных векторов и HOG. Затем она переходит к классическим архитектурам свёрточных нейронных сетей и пионерским моделям детектирования — Overfeat и DPM.
Глубокое понимание классических методов — не историческая экзотика, а рабочая основа для осмысленного применения современных нейросетевых детекторов.
В постоянно развивающейся области искусственного интеллекта компьютерное зрение является ключевой дисциплиной. Хотя современное компьютерное зрение доминируется методами глубокого обучения, важно понимать, что его история предшествует подъёму нейронных сетей. HOG и Selective Search остаются отличными инструментами для понимания принципов, на которых строятся YOLO, Faster R-CNN и все современные детекторы.
В следующей части серии — свёрточные нейронные сети (CNN), которые вывели детектирование объектов на принципиально новый уровень.