Предсказание цен акций с RNN: часть 2
Разбираем туториал Lilian Weng: добавляем эмбеддинги тикеров в LSTM-модель и учим одну сеть предсказывать цены сразу 100 акций.
Что было в первой части — и почему этого мало
В первом туториале Lilian Weng построила рекуррентную нейросеть на основе LSTM-ячеек для предсказания цен одной акции. Модель работала: она обучалась на скользящих окнах нормализованных цен и выдавала прогноз на несколько дней вперёд. Но у неё был существенный изъян — она понятия не имела, какую именно акцию предсказывает.
Представьте, что один специалист одновременно ведёт 100 клиентов, но не помнит, кто есть кто. Каждый разговор начинается с нуля. Именно так работала модель из Part 1 применительно к разным тикерам: никакой памяти о личности «клиента».
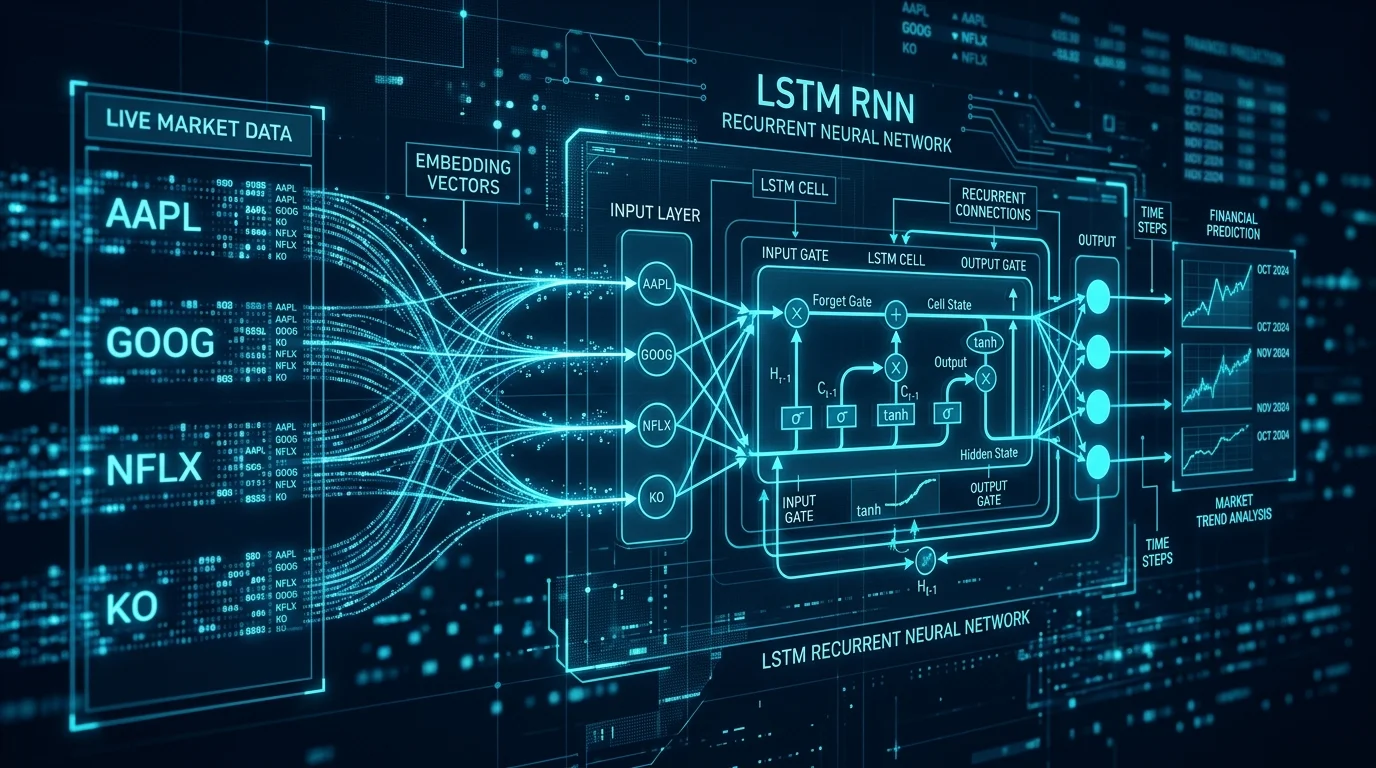
В Part 2 цель — наделить рекуррентную нейросеть из первой части способностью работать сразу с несколькими акциями. Решение элегантное и хорошо известное в NLP — эмбеддинги символов.
Почему одна модель на все акции — это умно
Наивный подход: обучить отдельную LSTM для каждой акции. Проблема очевидна — 500 акций S&P 500 означают 500 независимых моделей, 500 процессов обучения и нулевой перенос знаний между ними.
Альтернатива из Part 2: обучить одну модель, которая видит данные всех акций сразу, но при каждом входе знает, о каком тикере идёт речь. Это позволяет:
- Учиться на значительно большем объёме данных
- Переносить паттерны (например, реакция на макрособытия) между похожими акциями
- Экономить ресурсы при инференсе
Чтобы модель могла различать паттерны разных ценовых последовательностей, символы акций используются в качестве векторов эмбеддингов — части входных данных.
Эмбеддинг тикера — это «удостоверение личности» акции, которое модель учится формировать сама в процессе обучения.
Эмбеддинги тикеров: как это работает
Идея пришла из обработки естественного языка. Там слова кодируются не разреженными one-hot векторами, а плотными числовыми представлениями — эмбеддингами. Для акций логика та же.
Шаг 1: Label Encoding тикеров
Для каждого входного ценового ряда добавляется плейсхолдер — список символов акций, которые заранее маппируются в уникальные целые числа с помощью label encoding.
# Псевдокод: маппинг тикеров в индексы
stock_symbols = ['AAPL', 'GOOG', 'NFLX', 'KO', ...]
stock_to_id = {sym: i for i, sym in enumerate(stock_symbols)}
# AAPL -> 0, GOOG -> 1, NFLX -> 2, ...
Шаг 2: Матрица эмбеддингов
В конфигурацию модели RNNConfig добавляются два параметра: embedding_size — размер каждого вектора эмбеддинга, и stock_count — количество уникальных акций в датасете. Вместе они определяют размер матрицы эмбеддингов: модель должна обучить embedding_size × stock_count дополнительных переменных по сравнению с моделью из Part 1.
class RNNConfig():
# ... старые параметры ...
embedding_size = 3 # размер вектора на акцию
stock_count = 50 # число уникальных тикеров
Шаг 3: Конкатенация с ценовыми данными
Альтернатива — конкатенировать вектор эмбеддинга с последним состоянием LSTM-ячейки и учить новые веса в выходном слое. Однако в таком случае LSTM не сможет различать цены одной акции от другой, и её мощь будет существенно ограничена. Поэтому выбран первый подход — подавать эмбеддинг прямо на вход LSTM, конкатенируя его с ценовыми фичами на каждом шаге.
graph TD
A["Тикер: 'AAPL' → ID: 0"] --> B["Матрица эмбеддингов\n(stock_count × embed_size)"]
B --> C["Вектор эмбеддинга\n[0.12, -0.45, 0.89]"]
D["Ценовые данные\n[P_t, P_t-1, P_t-2]\n(input_size=3)"] --> E["Конкатенация"]
C --> E
E --> F["LSTM ячейки\n(lstm_size=256)"]
F --> G["Выходной слой\n(Dense)"]
G --> H["Предсказание цены"]
Данные и конфигурация эксперимента
Получение исторических данных
Сначала загружаются полные данные S&P 500 с Yahoo Finance (файл SP500.csv), затем скрипт data_fetcher.py скачивает котировки каждой отдельной акции в отдельный CSV-файл.
Датасет содержит поля: цена открытия, максимум, минимум, цена закрытия, скорректированная цена закрытия и объём торгов.
Нормализация: предсказываем изменения, а не цены
Чтобы решить проблему выхода за пределы обучающей выборки, цены нормализуются в каждом скользящем окне. Задача превращается в предсказание относительных изменений, а не абсолютных значений.
Гиперпараметры эксперимента
В эксперименте с 100 акциями используется следующая конфигурация: stock_count=100, input_size=3, embed_size=3, num_steps=30, lstm_size=256, num_layers=1, max_epoch=50, keep_prob=0.8, batch_size=64, init_learning_rate=0.05, learning_rate_decay=0.99.
| Параметр | Значение | Описание |
|---|---|---|
stock_count | 100 | Число уникальных тикеров |
embed_size | 3 | Размер вектора эмбеддинга |
input_size | 3 | Количество входных цен (дней) |
num_steps | 30 | Длина последовательности (шагов LSTM) |
lstm_size | 256 | Размер скрытого состояния LSTM |
keep_prob | 0.8 | Вероятность дропаута (1 - dropout rate) |
batch_size | 64 | Размер мини-батча |
max_epoch | 50 | Максимальное число эпох |
Архитектура модели и обучение
LSTM с дропаутом
Модель LSTM имеет num_layers стопок LSTM-слоёв, каждый из которых содержит lstm_size ячеек. Затем к выходу каждой ячейки применяется маска дропаута с вероятностью сохранения keep_prob.
# Упрощённый пример на TensorFlow 2.x / Keras
import tensorflow as tf
def build_model(stock_count, embed_size, input_size,
lstm_size, num_layers, keep_prob):
# Входы
price_input = tf.keras.Input(shape=(None, input_size), name='prices')
symbol_input = tf.keras.Input(shape=(None,), dtype='int32', name='symbols')
# Эмбеддинги тикеров
embed = tf.keras.layers.Embedding(
input_dim=stock_count,
output_dim=embed_size,
name='stock_embedding'
)(symbol_input)
# Конкатенируем с ценами
merged = tf.keras.layers.Concatenate()([price_input, embed])
# Стек LSTM с дропаутом
x = merged
for _ in range(num_layers):
x = tf.keras.layers.LSTM(
lstm_size, return_sequences=True,
dropout=1 - keep_prob
)(x)
# Выходной слой
output = tf.keras.layers.Dense(1)(x)
return tf.keras.Model([price_input, symbol_input], output)
Оптимизатор и функция потерь
В оригинальной реализации используется оптимизатор RMSProp. Функция потерь — среднеквадратическая ошибка (MSE), что стандартно для задач регрессии на временных рядах.
Результаты: что показала модель
Для оценки качества предсказания строятся графики для тестовых данных акций KO, AAPL, GOOG и NFLX — и общие тренды совпадают с реальными значениями.
Принимая во внимание дизайн задачи, модель опирается на все исторические точки для предсказания только следующих 5 дней (параметр input_size). При малом input_size модели не нужно беспокоиться о долгосрочной динамике роста. Если увеличить input_size, задача становится значительно сложнее.
Ключевые наблюдения
- Краткосрочные тренды предсказываются лучше, чем долгосрочные — классическое поведение LSTM на финансовых рядах
- Подход использует мощь LSTM-сетей для захвата временных зависимостей в последовательных данных, что хорошо подходит для предсказания цен акций.
- Эмбеддинги помогают модели «запомнить характер» каждой акции — её волатильность, реакцию на новости, типичные паттерны
Что можно улучшить и как применить это сегодня
Важно подчеркнуть: мотивация туториала — показать, как строить и обучать RNN-модель, а не решить задачу предсказания акций наилучшим образом. Это честное признание, которое открывает дорогу к множеству улучшений.
Современные направления развития
| Направление | Идея | Ожидаемый эффект |
|---|---|---|
| Мультивариантный вход | Добавить объём, OHLC вместо только Close | +10–20% точности |
| Attention-механизм | Трансформер поверх LSTM | Лучше улавливает дальние зависимости |
| Сентимент-анализ | FinBERT эмбеддинги новостей | Улавливает событийную составляющую |
| Более богатые эмбеддинги | Сектор, капитализация как доп. фичи | Лучшая группировка похожих акций |
| Ансамблирование | LSTM + градиентный бустинг | Снижает дисперсию ошибки |
Популярный современный подход — скользящее окно размером 60 торговых дней, где каждая входная последовательность соответствует целевому значению 61-го дня.
Фондовый рынок крайне волатилен и трудно поддаётся точному прогнозу из-за множества неопределённостей. Тем не менее инвесторы и трейдеры могут выигрывать от таких моделей, принимая обоснованные решения о покупке, удержании или продаже акций. Финансовые институты также используют подобные модели для управления рисками и оптимизации инвестиционных портфелей.
Заключение
Part 2 туториала Lilian Weng делает важный концептуальный шаг: модель перестаёт быть «слепой» относительно того, чьи цены она предсказывает. Добавление эмбеддингов тикеров — это не просто техническая деталь, а архитектурное решение, которое позволяет одной сети аккумулировать знания о сотнях инструментов одновременно.
Главные выводы:
- Эмбеддинги — универсальный инструмент: то, что работает для слов в NLP, отлично работает для тикеров в финансах
- Нормализация внутри окна критична — без неё модель не обобщается на новые ценовые уровни
- Один
input_sizeопределяет горизонт прогноза: маленький — проще задача, большой — нужна более сложная архитектура - Качество данных и фичинг важнее архитектуры: лучший эмбеддинг с правильными фичами обгонит сложную сеть на плохих данных
Архитектурные паттерны из этого туториала живут в современных моделях — только LSTM сегодня всё чаще заменяется трансформером, а эмбеддинги тикеров обогащаются фундаментальными данными о компании. Фундамент, заложенный здесь, по-прежнему актуален.