Self-Supervised Representation Learning: полное руководство
Что такое Self-Supervised Representation Learning, как работают контрастивные методы, MAE, DINO и BYOL, и почему SSRL меняет правила игры в ML.
Почему разметка данных — это узкое горло AI
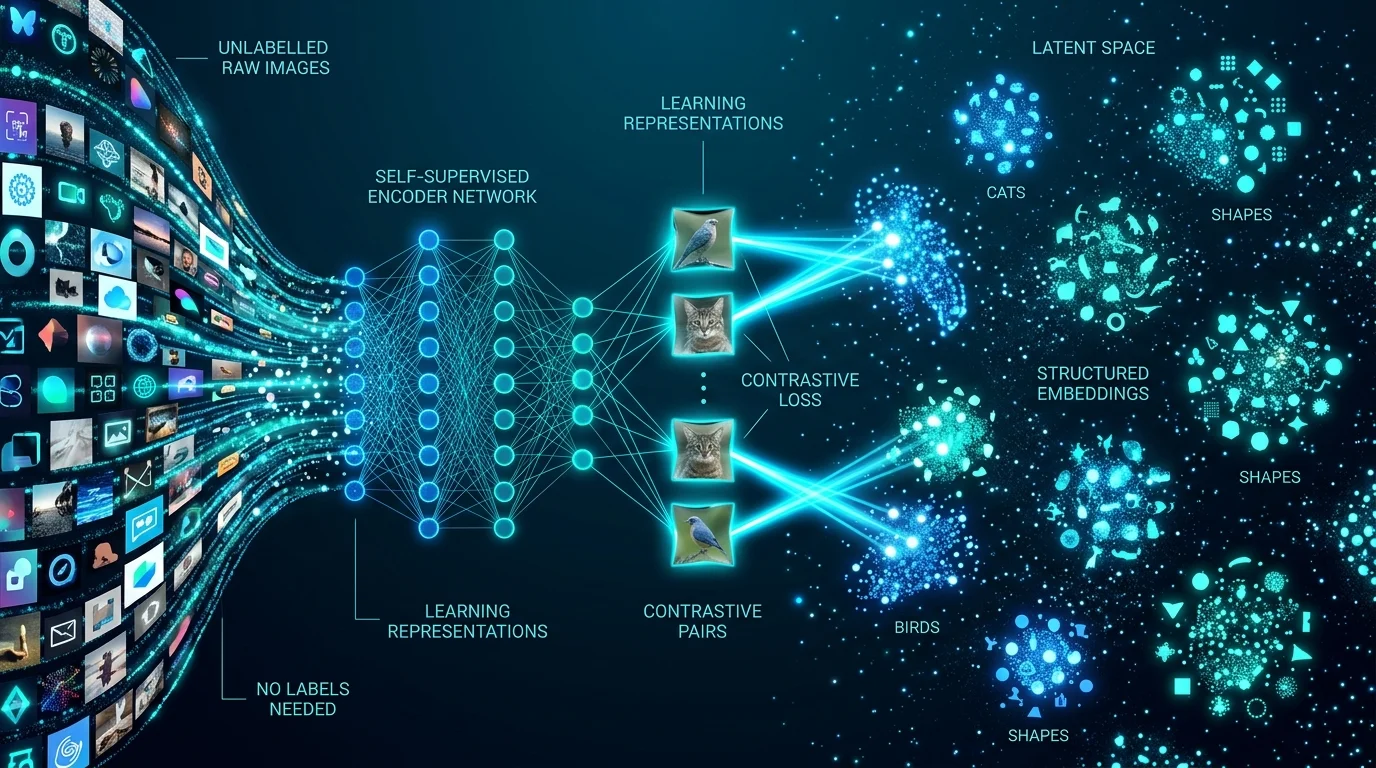
Представьте: у вас есть миллиард фотографий из интернета, но на каждую нужно поставить метку «кошка / собака / машина». Вручную это займёт годы и обойдётся в десятки миллионов долларов. Именно здесь появляется Self-Supervised Representation Learning (SSRL) — подход, который учит нейросеть понимать мир без единой человеческой метки.
SSRL — это подмножество методов обучения без учителя, где модели извлекают полезные признаковые представления из данных без необходимости в размеченных образцах. Иными словами, нейросеть сама придумывает себе задачи, решает их и в процессе учится понимать структуру данных.
Как работает SSRL: pretext-задачи и supervisory signal
SSRL обучает модели, используя supervisory signals, автоматически генерируемые из неразмеченных данных через pretext-задачи (задачи-прелюдии). Эти задачи заставляют глубокие нейросети извлекать содержательные признаки.
Простыми словами: вместо того чтобы спрашивать «это кошка?», мы спрашиваем «на сколько градусов повёрнуто это изображение?» или «какой цвет был у этого серого пикселя?». Отвечая на такие вопросы, модель вынуждена разобраться в структуре изображения.
Классические pretext-задачи включают раскрашивание изображений, предсказание поворота и предсказание относительного положения патчей — при этом псевдо-метки генерируются автоматически из самих данных.
В обработке речи применяются задачи маскированной реконструкции — часть mel-спектрограммы скрывается, и модель учится её восстанавливать.
graph TD
A[Исходные данные без меток] --> B[Pretext-задача\nавтоматически]
B --> C{Тип задачи}
C --> D[Контрастивное обучение\nSimCLR / MoCo]
C --> E[Генеративное маскирование\nMAE / BERT]
C --> F[Дистилляция знаний\nBYOL / DINO]
D --> G[Признаковые представления]
E --> G
F --> G
G --> H[Fine-tuning на downstream-задаче]
H --> I[Классификация / Детекция / Сегментация]
Три главные парадигмы SSRL
1. Контрастивное обучение: SimCLR и MoCo
В контрастивных методах берут разные виды одних и тех же данных (например, два аугментированных вида одного изображения) и максимизируют их сходство, одновременно минимизируя сходство с другими образцами.
SimCLR (Simple Contrastive Learning of Representations) — один из первых мощных контрастивных фреймворков:
SimCLR учится, максимизируя сходство между по-разному аугментированными видами одного образца и минимизируя сходство с другими изображениями через контрастивный loss. Два аугментированных изображения прогоняются через энкодер, затем применяется нелинейный fully connected слой для получения представлений — и цель состоит в максимизации их сходства.
import torch
import torch.nn.functional as F
def nt_xent_loss(z1, z2, temperature=0.5):
"""
NT-Xent loss (SimCLR)
z1, z2: нормализованные эмбеддинги [batch_size, dim]
"""
batch_size = z1.shape[0]
# Конкатенируем оба вида
z = torch.cat([z1, z2], dim=0) # [2*B, dim]
# Матрица сходства
sim = F.cosine_similarity(z.unsqueeze(1), z.unsqueeze(0), dim=2)
sim = sim / temperature
# Маска для исключения диагонали
mask = torch.eye(2 * batch_size, dtype=bool)
sim.masked_fill_(mask, float('-inf'))
# Позитивные пары: i и i+B
labels = torch.arange(batch_size)
labels = torch.cat([labels + batch_size, labels])
loss = F.cross_entropy(sim, labels)
return loss
MoCo первым предложил концепцию momentum contrast: пара аугментаций одного образца считается позитивной, все остальные образцы и их аугментации — негативными, что позволяет проводить контрастивное обучение на неразмеченных данных.
2. Неконтрастивные методы: BYOL и DINO
Неконтрастивные методы не используют негативные образцы. BYOL и DINO — хрестоматийные примеры таких методов, тогда как SimCLR и MoCo требуют негативных примеров.
BYOL состоит из двух нейросетей: online- и target-сети. Они взаимодействуют и учатся друг у друга: аугментированный вид изображения подаётся в online-сеть, чтобы предсказать представление target-сети для другого аугментированного вида того же изображения. При этом target-сеть обновляется как медленно движущееся среднее online-сети.
«Bootstrap Your Own Latent» — модель буквально «тянет себя за шнурки», улучшая представления без единого негативного примера.
DINO обучает модель так, что её attention-маски способны обнаруживать сложные признаки сцены, а получаемые эмбеддинги можно использовать напрямую — например, как маски сегментации — что позволяет DINO хорошо справляться с downstream-задачами даже с kNN-классификатором.
3. Masked Autoencoders (MAE): генеративный подход
MAE, вдохновлённый успехом masked language modeling в NLP, маскирует высокую долю патчей входного изображения и обучает модель восстанавливать пропущенные пиксели.
Архитектура использует асимметричный encoder-decoder: энкодер работает только с видимыми патчами (без mask tokens), а лёгкий декодер восстанавливает исходное изображение. При этом маскируется 75% входного изображения — нетривиальная задача, вынуждающая модель понять глобальную структуру.
Сила подхода в его простоте: не нужны контрастивные loss-функции, негативные пары, momentum-учителя или специфические эвристики. Задача концептуально прямолинейна: скрой большую часть изображения и предскажи её — и это создаёт чрезвычайно эффективный обучающий сигнал.
В NLP генеративные pretext-задачи с masked prediction (например, BERT) стали де-факто стандартом. В компьютерном зрении ранние попытки генеративных методов были вытеснены дискриминативными (контрастивными), однако успех masked image modeling возродил интерес к маскированным автоэнкодерам.
Сравнение ключевых методов SSRL
| Метод | Парадигма | Негативные примеры | Backbone | Top-1 ImageNet (fine-tune) |
|---|---|---|---|---|
| SimCLR v2 | Контрастивный | ✅ Да | ResNet | ~76–79% |
| MoCo v3 | Контрастивный | ✅ Да | ViT | ~83.2% |
| BYOL | Неконтрастивный | ❌ Нет | ResNet/ViT | ~74–80% |
| DINO | Дистилляция | ❌ Нет | ViT | ~82.8% |
| DINOv2 | Дистилляция | ❌ Нет | ViT-G | ~86.3% |
| MAE | Генеративный | ❌ Нет | ViT-H | 87.8% |
| BEiT | Генеративный | ❌ Нет | ViT | ~86.3% |
Современные SSL-методы достигают и превосходят качество supervised learning на ряде бенчмарков: MAE ViT-Huge достиг 87.8% top-1 accuracy на ImageNet, используя только 1K данных для fine-tuning.
Где применяется SSRL на практике
SSRL обеспечил значительный прогресс в различных областях компьютерных наук, позволяя pre-train модели на масштабных неразмеченных датасетах и fine-tune на downstream-задачах, снижая потребность в дорогостоящей разметке.
Компьютерное зрение
В computer vision SSRL улучшил классификацию изображений, детекцию объектов и сегментацию, обучая признаковые представления через pretext-задачи.
Медицина и здравоохранение
Широкое распространение электронных медицинских карт и deep learning, особенно через SSRL, трансформировало клиническое принятие решений. Основные тренды в моделях для медицины: Transformer-based (43%), Autoencoder-based (28%) и Graph Neural Network-based (17%).
Робототехника
В робототехнике и imitation learning SSRL позволяет роботам обучаться навыкам взаимодействия с объектами из неразмеченных видео, преодолевая разницу в воплощении и угле обзора.
Промышленность и веб
Промышленные и веб-приложения выигрывают от SSRL в задачах обнаружения ботов, групповых рекомендаций и персонализированного поиска.
Задача: классификация рентгеновских снимков при наличии только 500 размеченных изображений.
Решение с SSRL:
- Pre-train DINO или MAE на 500 000 неразмеченных рентгеновских снимков
- Fine-tune на 500 размеченных изображениях
- Получить точность, сравнимую с полностью supervised моделью на 50 000 примерах
Экономия: в 100× меньше разметки.
Ключевые инсайты и ограничения
Исследования выявили несколько ключевых закономерностей: (1) стратегия аугментации данных важнее выбора SSL-парадигмы; (2) Vision Transformers выигрывают от SSL pre-training; (3) masked image modeling обеспечивает простоту и эффективность; (4) масштабирование на большие модели и датасеты улучшает результат.
- Вычислительные затраты: pre-training крупных моделей (DINO, MAE) требует сотен GPU-часов
- Зависимость от аугментаций: выбор аугментаций критически влияет на качество контрастивных методов
- Коллапс представлений: без специальных механизмов (stop-gradient, momentum encoder) модель может выучить тривиальное решение
- DINO требует больших вычислительных ресурсов и объёма данных, что затрудняет обучение собственных моделей для большинства исследователей.
Проблема коллапса
Методы контрастивного обучения стремятся максимизировать сходство двух аугментаций одного изображения, одновременно предотвращая коллапс — тривиальное решение, при котором всем изображениям датасета присваивается один и тот же вектор представления. Различные методы отличаются способом предотвращения этого коллапса.
SimCLR решает проблему через негативные пары; MoCo, BYOL и DINO используют momentum encoder; SwAV прибегает к внешнему алгоритму кластеризации.
Заключение: SSL как новый фундамент AI
Self-Supervised Representation Learning — не просто академическая концепция. Это практический инструмент, который уже лежит в основе GPT, BERT, CLIP, DINO и многих других моделей, определяющих современный AI.
Главные выводы:
- Pretext-задачи — мощный источник бесплатного обучающего сигнала из любых неразмеченных данных
- Контрастивные методы (SimCLR, MoCo) эффективны, но требуют негативных примеров и больших батчей
- BYOL и DINO уходят от негативных примеров через дистилляцию знаний
- MAE показывает, что простая задача реконструкции при маскировании 75% входа даёт SOTA-результаты
- SSL-модели уже превосходят supervised baseline на ряде бенчмарков
Self-supervised learning — это не обходной путь. Это то, как учится интеллект: находя структуру в мире без чужих подсказок.
С ростом масштабов неразмеченных данных и вычислительных мощностей SSRL будет только укреплять свои позиции как центральная парадигма обучения репрезентаций — от компьютерного зрения до медицины, робототехники и за их пределами.