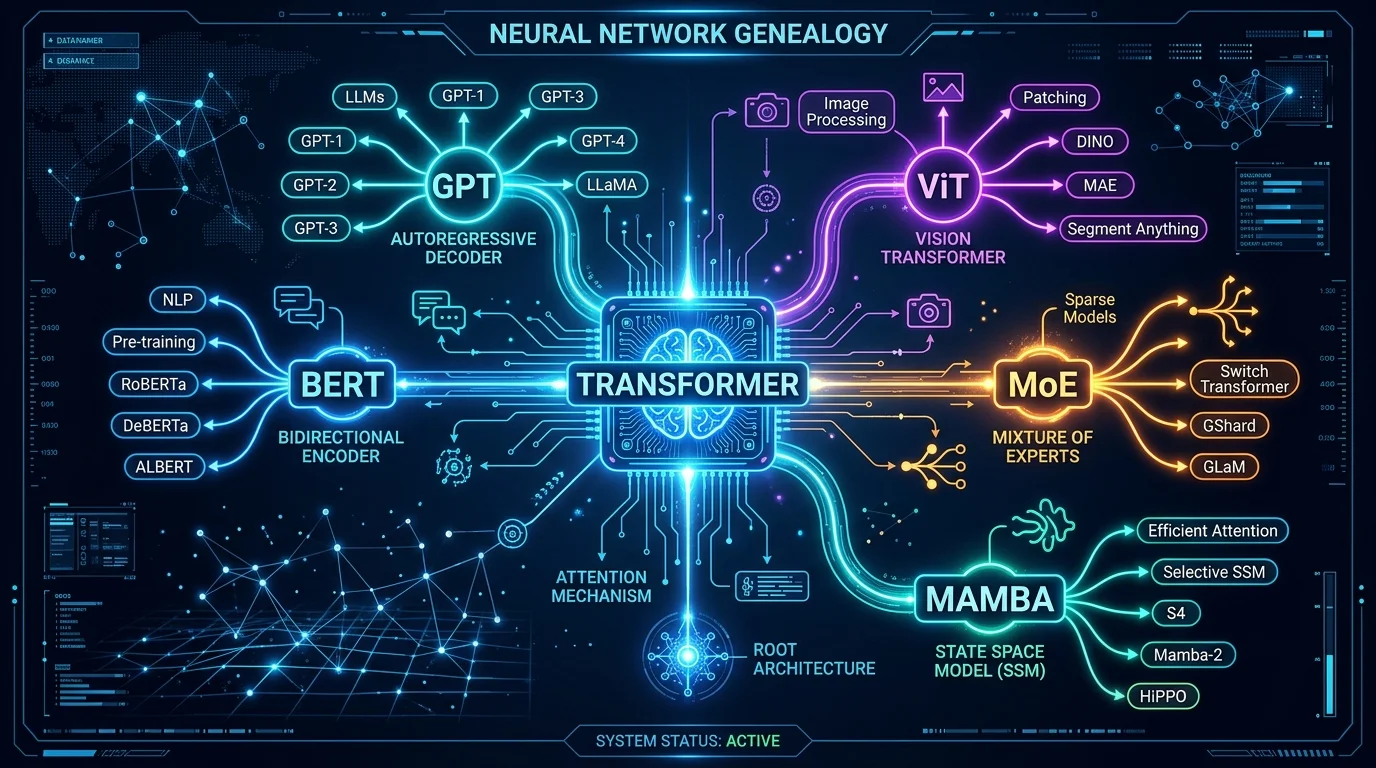
Семейство Трансформеров: от BERT до MoE и Mamba
Полный гид по архитектурам семейства Transformer: от оригинала 2017 года до MoE, ViT и постТрансформерных моделей 2024–2025.
Семейство Трансформеров: от «Attention Is All You Need» до MoE и Mamba
В 2017 году команда Google опубликовала статью с простым названием «Attention Is All You Need». Мало кто предполагал, что эта работа породит целую династию архитектур, которая через восемь лет будет лежать в основе ChatGPT, Gemini, Stable Diffusion и сотен других систем. Сегодня, в 2026 году, практически всё современное глубокое обучение строится на Трансформере в той или иной форме.
Эта статья — системный обзор «семейства Трансформеров»: откуда оно появилось, какие ветви дало и куда движется дальше.
1. Оригинальная архитектура: что такое Трансформер
Оригинальная архитектура Трансформера была предложена в 2017 году в статье «Attention Is All You Need» исследователями Google. Ключевая идея — полностью отказаться от рекуррентных сетей.
Трансформер ввёл принципиально новый подход к моделированию последовательностей: вместо рекуррентности и свёрток — механизм само-внимания (self-attention). Благодаря отсутствию рекуррентных блоков Трансформеры требуют значительно меньше времени на обучение, чем более ранние рекуррентные архитектуры вроде LSTM.
Строительные блоки классического Трансформера:
- Токенизация и эмбеддинги — слова преобразуются в числовые векторы
- Позиционное кодирование — сеть «узнаёт» порядок токенов
- Multi-Head Attention — параллельный расчёт внимания по нескольким «головам»
- Feed-Forward слои — нелинейные преобразования поверх внимания
- Нормализация слоёв и остаточные связи — стабильность обучения
Энкодер Трансформера состоит из стеков, каждый с двумя компонентами: после механизма само-внимания информация нормируется и передаётся в слой сети прямого распространения.
Современные дизайны Трансформеров принято делить на три группы: encoder-only, decoder-only и encoder-decoder — в зависимости от того, оптимизированы ли они для обучения представлениям, авторегрессивной генерации или задач sequence-to-sequence.
2. Три главные ветви: BERT, GPT и T5
Из одного корня выросли два принципиально разных направления — и затем гибридное третье.
BERT — понимание контекста
BERT (Bidirectional Encoder Representations from Transformers) вышел 11 октября 2018 года. Как следует из названия, BERT — двунаправленная модель: механизм внимания может обращаться к обоим направлениям относительно текущего токена. Это достигается благодаря стеку из 12 энкодеров, то есть BERT является encoder-only архитектурой.
BERT использует многослойный двунаправленный энкодер Трансформера с механизмом само-внимания. Это позволяет BERT оценивать важность разных слов в предложении. Архитектура BERT состоит из двух стадий: предобучение и файн-тюнинг. На этапе предобучения модель обрабатывает огромные корпуса текста — Books Corpus и английскую Википедию.
Encoder-only архитектура применяется в BERT и его вариантах — главным образом для задач классификации, ответов на вопросы и построения эмбеддингов.
GPT — генерация текста
GPT (Generative Pre-trained Transformer) использует однонаправленную архитектуру Трансформера для предобучения языковой модели. Файн-тюнинг GPT на конкретных задачах давал существенное улучшение, а последующие итерации — GPT-2, GPT-3 и GPT-4 — продолжали двигать state-of-the-art.
Decoder-only архитектура используется в GPT и LLaMA — прежде всего для генерации текста, саммаризации и чата.
В конце 2022 года ChatGPT — чат-бот на основе файн-тюнинга GPT-3.5 — неожиданно приобрёл огромную популярность, дав толчок буму вокруг больших языковых моделей.
Сравнительная таблица: BERT vs GPT vs T5
| Параметр | BERT | GPT (семейство) | T5 |
|---|---|---|---|
| Архитектура | Encoder-only | Decoder-only | Encoder-Decoder |
| Направление внимания | Двунаправленное | Однонаправленное | Оба |
| Основные задачи | Классификация, QA, эмбеддинги | Генерация текста, чат | Перевод, саммаризация |
| Предобучение | Masked LM | Causal LM | Text-to-Text |
| Примеры моделей | RoBERTa, DeBERTa, ALBERT | GPT-4, LLaMA, Mistral | FLAN-T5, mT5 |
3. Трансформер выходит за пределы NLP: Vision Transformer и мультимодальность
Возможно, самым неожиданным шагом стало распространение Трансформера за пределы текста.
Vision Transformer (ViT) был представлен в 2021 году в исследовательской работе «An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale», опубликованной на ICLR 2021. Идея проста: нарезать изображение на патчи фиксированного размера и трактовать каждый патч как токен — ровно так же, как текстовый Трансформер обрабатывает слова.
Досовицкий и соавторы продемонстрировали применимость архитектуры Трансформера к задачам компьютерного зрения с помощью модели Vision Transformer (ViT). В свою очередь, Vision Transformer стимулировал новые разработки в области свёрточных нейронных сетей.
Трансформеры вышли далеко за пределы текста и нашли применение в зрении, распознавании речи, робототехнике и мультимодальных системах.
Генераторы изображений и видео, такие как DALL-E (2021), Stable Diffusion 3 (2024) и Sora (2024), используют Трансформеры для анализа входных данных, разбивая их на токены и вычисляя релевантность с помощью само-внимания.
graph TD
A["🧠 Transformer (2017)"] --> B["Encoder-only\nBERT, RoBERTa"]
A --> C["Decoder-only\nGPT, LLaMA, Mistral"]
A --> D["Encoder-Decoder\nT5, BART, FLAN"]
A --> E["Vision Transformer\nViT, DINO, SAM"]
A --> F["Multimodal\nDALL-E, Sora, Gemini"]
C --> G["MoE-архитектуры\nMixtral, DeepSeek"]
A --> H["Post-Transformer\nMamba, RWKV, RetNet"]
4. Эффективность и масштабирование: MoE, FlashAttention и другие инновации
По мере роста моделей обнаружилась серьёзная проблема: стандартное само-внимание масштабируется квадратично по длине последовательности.
Квадратичная сложность по длине последовательности создаёт серьёзные трудности при работе с длинными контекстами и большими моделями. Индустрия ответила сразу на нескольких фронтах.
FlashAttention: аппаратно-ориентированная оптимизация
FlashAttention — низкоуровневая оптимизация, повышающая производительность Трансформера на GPU. Она задействует SRAM (разделяемую память) GPU и примитивы уровня warp для устранения избыточных операций чтения/записи памяти. Результат — ускорение обучения и инференса в 2–4 раза, значительное снижение потребления памяти при длинных последовательностях без потери точности.
Mixture of Experts (MoE): умная маршрутизация
Архитектура MoE улучшает стандартный Трансформер, заменяя слои FFN на MoE-слои, где каждый входной токен активирует лишь подмножество экспертов. Разреженная активация позволяет масштабировать ёмкость модели без пропорционального увеличения вычислительных затрат.
MoE включает набор «экспертов» — нейросетей одинаковой архитектуры, но с разными весами — и «маршрутизатор» (router), который выбирает нужных экспертов. Конструкция обычно заменяет feed-forward сети в блоках Трансформера. Для обработки одного токена задействуется лишь ограниченное подмножество экспертов.
MoE пережил возрождение вместе с выходом Switch Transformer и Mixtral — в 2021 и 2024 годах соответственно.
# Упрощённая схема MoE-маршрутизации (псевдокод)
def moe_forward(x, experts, router):
# router выбирает top-k экспертов для токена
scores = router(x) # [batch, seq_len, num_experts]
top_k_indices = scores.topk(k=2, dim=-1).indices
output = 0
for expert_idx in top_k_indices:
output += experts[expert_idx](x) * scores[expert_idx]
return output
Архитектурные улучшения в современных LLM
К 2024 году архитектуры Трансформера претерпели существенные изменения в части стабильности обучения, вычислительной эффективности и файн-тюнинга. Среди ключевых улучшений, применяемых в современных моделях вроде LLaMA 3:
- RoPE (Rotary Position Embedding) — более гибкое позиционное кодирование
- GQA (Grouped Query Attention) — сокращение числа KV-голов для ускорения инференса
- SwiGLU активации — замена ReLU для лучшей аппроксимации
- RMSNorm — упрощённая нормализация вместо LayerNorm
- Pre-Norm — нормализация перед слоями, а не после
5. За горизонтом: пост-Трансформерные архитектуры
Пока одни исследователи шлифовали Трансформер, другие задались более радикальным вопросом.
Нужен ли нам вообще механизм внимания?
Ряд исследователей задался смелым вопросом: а нужно ли нам внимание? В 2024 году произошло возрождение рекуррентных архитектур и других подходов, способных улавливать дальние зависимости без полного механизма внимания.
Эти «пост-Трансформерные» архитектуры нередко имеют линейное масштабирование памяти и вычислений по умолчанию, что делает их привлекательными для крупномасштабного развёртывания — при условии сопоставимых возможностей.
Основные кандидаты:
Mamba (State Space Models) — SSM подходят к моделированию последовательностей, обучая непрерывную динамическую систему, дискретизируемую для обработки входных данных. Исследователи уже расширили Mamba на изображения в виде Vision Mamba.
RWKV — RWKV сочетает эффективное параллельное обучение Трансформеров с эффективным инференсом RNN, устраняя их ограничения.
RetNet — RetNet теоретически выводит связь между рекуррентностью и вниманием, одновременно достигая параллелизма обучения, низких затрат при инференсе и хорошей производительности.
| Архитектура | Сложность внимания | Параллельное обучение | Эффективный инференс |
|---|---|---|---|
| Transformer | O(n²) | ✅ | ❌ (KV-кэш растёт) |
| Mamba (SSM) | O(n) | ✅ (частично) | ✅ |
| RWKV | O(n) | ✅ | ✅ |
| RetNet | O(n) | ✅ | ✅ |
| Hybrid (Jamba) | O(n) + O(n²) | ✅ | ✅ |
6. Открытые vs закрытые: демократизация архитектур
Параллельно с архитектурными инновациями развивался важный социальный процесс.
Пока проприетарные модели привлекали внимание публики, параллельная open-source революция быстро демократизировала технологию Трансформеров. Ключевую роль сыграли такие платформы, как Hugging Face, а в 2023 году выход семейства LLaMA от Meta кардинально изменил ландшафт — разработчики получили доступ к state-of-the-art без зависимости от закрытых экосистем.
На протяжении 2024–2025 годов разработка open-source моделей стремительно ускорялась. Такие модели, как LLaMA 3.1 и LLaMA 4 от Meta, эффективные архитектуры от Mistral и модели рассуждения от DeepSeek доказали, что открытые модели могут не только сравниться с проприетарными, но и превзойти их.
Среди перспективных тенденций будущего — разреженность, модели Mixture of Experts и адаптивные вычисления, которые способны дополнительно улучшить Трансформеры.
Заключение: почему Трансформер не сдаётся
Секрет доминирования Трансформера — в его гибкости и универсальности при работе с данными любой модальности, способности масштабироваться с ростом данных и параметров, «эмерджентных» возможностях и обучении в контексте.
За восемь лет из одной статьи выросло целое семейство:
- BERT научил модели понимать контекст
- GPT — генерировать связный текст в нужном стиле
- ViT — видеть и интерпретировать изображения
- T5 и BART — трансформировать текст в текст
- MoE-архитектуры — масштабироваться без взрывного роста вычислений
- Mamba, RWKV, RetNet — бросить вызов самому механизму внимания
Даже в 2025 году Трансформер остаётся сердцем генеративного AI, NLP и мультимодальных систем — но это уже «трансформированный Трансформер»: оснащённый FlashAttention, сжатый, оптимизированный и при случае замещаемый более лёгкими специализированными архитектурами.
Изучать это семейство — значит понимать современный AI в его основе. Архитектура меняется, но принцип «внимание — это всё» остаётся удивительно живучим.