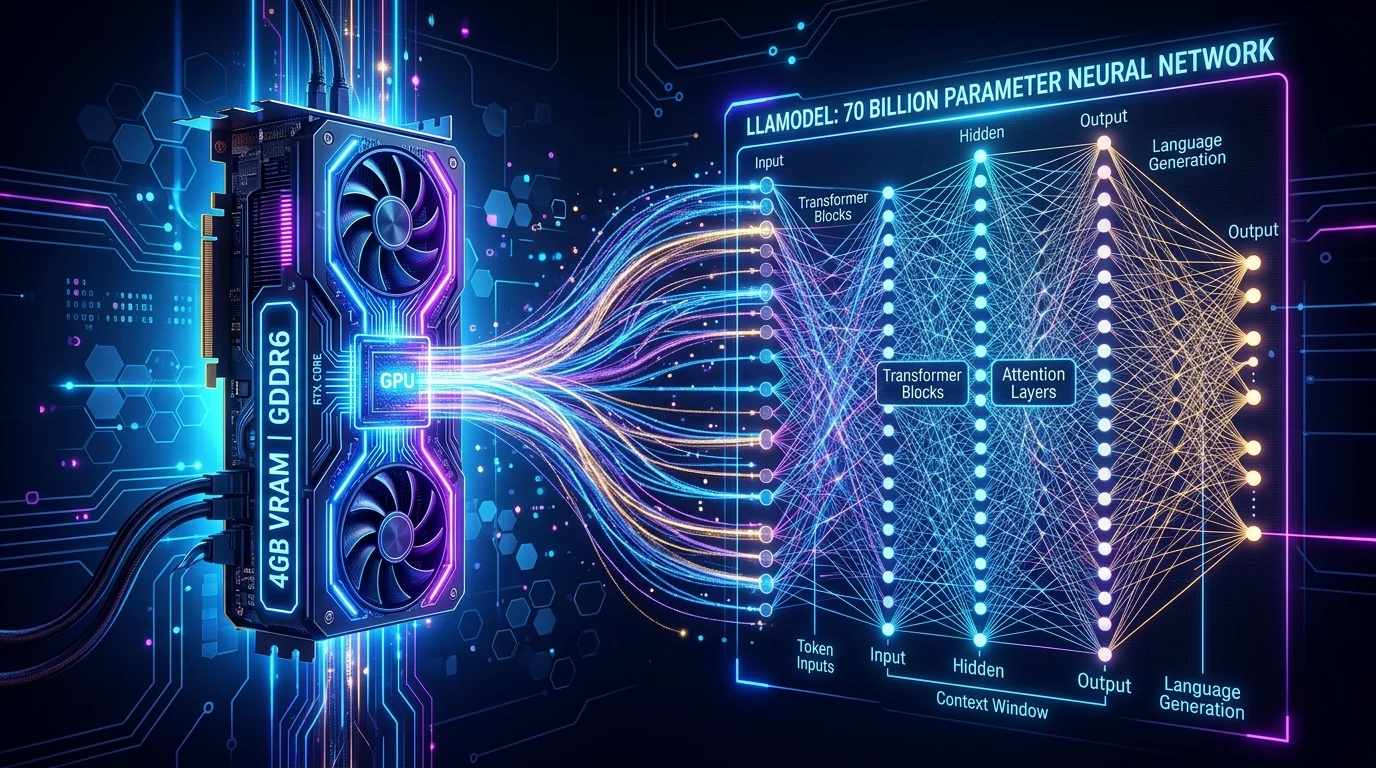
AirLLM: запуск 70B модели на GPU с 4 ГБ VRAM
AirLLM позволяет запускать 70B языковые модели на одной GPU с 4 ГБ VRAM без квантизации и прунинга — через послойную загрузку весов.
70B модель на бюджетной видеокарте — это реально
AirLLM — open-source инструмент, который даёт возможность запускать языковые модели с 70 миллиардами параметров на одной GPU с всего лишь 4 ГБ видеопамяти. И всё это без квантизации (quantization), дистилляции (distillation) или прунинга (pruning) — техник, которые обычно применяются для «облегчения» моделей ценой потери точности. А в последних версиях планка поднялась ещё выше: Llama 3.1 на 405 миллиардов параметров теперь работает на GPU с 8 ГБ VRAM.
Нет нужды в дорогом железе — AirLLM делает мощные модели доступными для любого разработчика с обычной видеокартой.
Как это работает: послойная загрузка
Секрет AirLLM — в технике layer-wise inference (послойный инференс). Обычный подход загружает все веса модели в VRAM сразу. Модель на 70B параметров весит около 140 ГБ — и стандартная 4 ГБ видеокарта с таким объёмом справиться не может.
AirLLM действует иначе: веса модели хранятся на SSD, а в GPU загружается только один слой трансформера за раз. После вычисления слой выгружается, загружается следующий. Каждый слой занимает около 1.6 ГБ VRAM — это укладывается даже в самые скромные видеокарты.
graph LR
A[SSD: веса модели] -->|загрузка слоя| B[GPU VRAM 4GB]
B -->|вычисление| C[Выход слоя N]
C -->|выгрузка| D[Следующий слой]
D --> B
C -->|финальный токен| E[Результат]
Предзагрузка (prefetching), добавленная в v2.5, перекрывает загрузку следующего слоя с вычислением текущего — это дало прирост скорости около 10%.
Быстрый старт: три шага
pip install airllm
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel.from_pretrained("garage-bAInd/Platypus2-70B-instruct")
input_text = ['What is the capital of United States?']
input_tokens = model.tokenizer(
input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=False
)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=20,
use_cache=True,
return_dict_in_generate=True
)
print(model.tokenizer.decode(generation_output.sequences[0]))
Компрессия: ускорение до 3x
AirLLM поддерживает блочную квантизацию весов (block-wise quantization) — не активаций, а только весов. Это принципиальное отличие от классической квантизации: поскольку узкое место — загрузка с диска, а не сами вычисления, достаточно сжать только веса. Результат — ускорение инференса до 3x при минимальной потере точности.
model = AutoModel.from_pretrained(
"garage-bAInd/Platypus2-70B-instruct",
compression='4bit' # или '8bit'
)
Поддерживаемые модели и платформы
| Модель / Семейство | Поддержка |
|---|---|
| Llama 2 / 3 / 3.1 (до 405B) | ✅ |
| Mixtral | ✅ |
| Qwen / Qwen2.5 | ✅ |
| ChatGLM | ✅ |
| Baichuan / InternLM | ✅ |
| Mistral | ✅ |
| CPU inference | ✅ (v2.10.1+) |
| MacOS (Apple Silicon) | ✅ (v2.8.2+) |
mlx и torch, затем запускайте так же, как на Linux.Параметры инициализации
| Параметр | Описание |
|---|---|
compression | '4bit' / '8bit' — блочная квантизация весов |
layer_shards_saving_path | Путь для сохранения разбитой модели |
hf_token | Токен HuggingFace для приватных моделей |
prefetching | Предзагрузка слоёв (по умолчанию включена) |
delete_original | Удалить исходную модель после разбивки |
profiling_mode | Вывод времени выполнения этапов |
Почему это важно для отрасли
До появления AirLLM запуск 70B модели требовал видеокарты с 24 ГБ VRAM и выше — это оборудование стоимостью тысячи долларов. Теперь тот же результат достижим на потребительском GPU за $200–300. Как отмечают наблюдатели, это означает, что исследователь с минимальным оборудованием получает доступ к тем же мощным моделям, что и владелец дорогостоящей рабочей станции.
Плата за доступность — скорость. CPU inference даёт порядка 200–500 секунд на токен для больших моделей. Но для задач, где скорость некритична — разовые вычисления, исследования, эксперименты — это полностью рабочее решение.
Проект распространяется под лицензией Apache 2.0, код доступен на GitHub.