HuggingFace Transformers: единый стандарт для AI-моделей
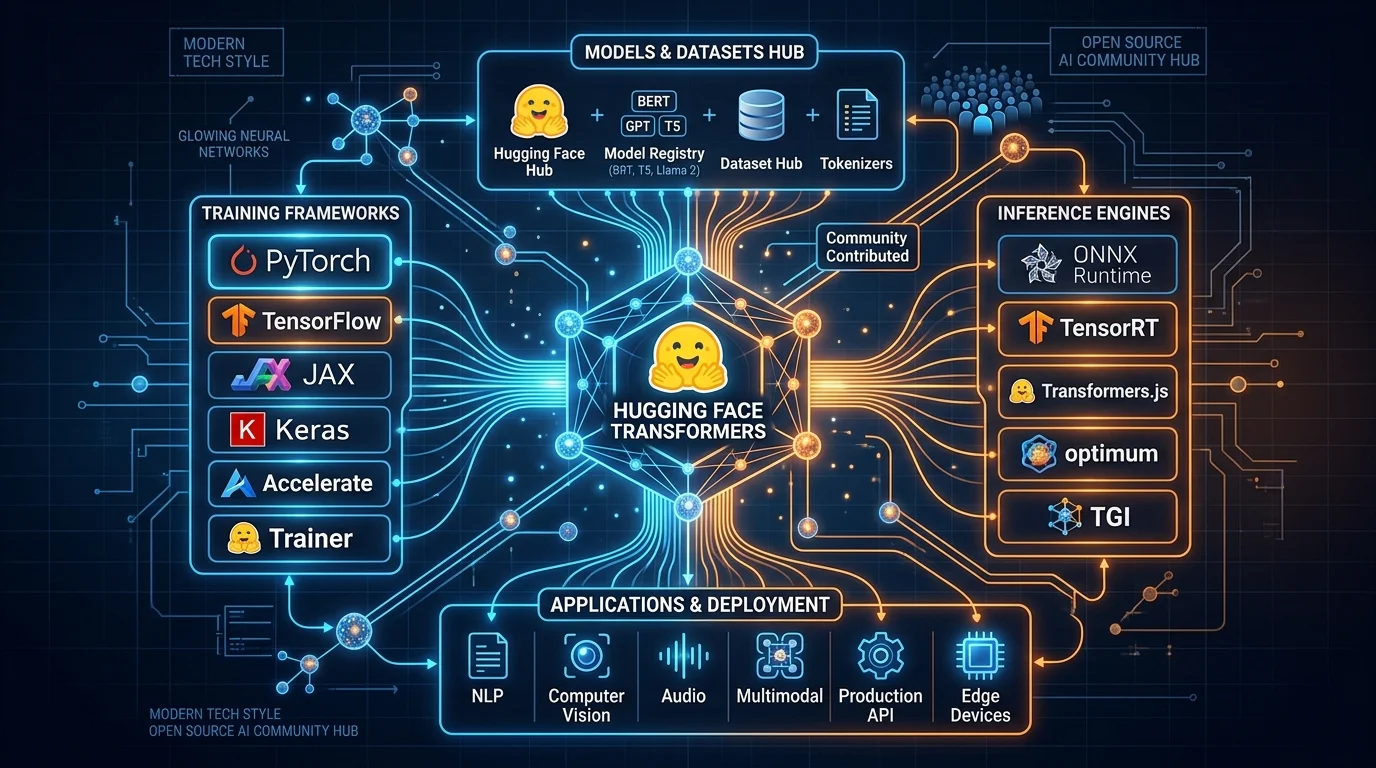
Hugging Face Transformers — центральная библиотека для работы с LLM, VLM и мультимодальными моделями. Более 1 млн чекпоинтов, 3 млн установок в день.
HuggingFace Transformers: единый стандарт для AI-моделей
Hugging Face Transformers — это не просто библиотека, а фундамент всей современной экосистемы машинного обучения с открытым исходным кодом. Сегодня библиотека фиксирует более трёх миллионов установок в день и суммарно преодолела отметку в 1,2 миллиарда установок. Это де-факто единый стандарт описания моделей для обучения, инференса и деплоя — от исследовательских экспериментов до продакшена крупных компаний.
Что такое Transformers и зачем он нужен
Transformers выступает фреймворком определения моделей для машинного обучения: он охватывает задачи с текстом, компьютерным зрением, аудио, видео и мультимодальными данными — как для инференса, так и для обучения — и централизует описание модели, согласованное по всей экосистеме.
Если архитектура модели поддерживается в transformers, она автоматически совместима с большинством фреймворков обучения — Axolotl, Unsloth, DeepSpeed, FSDP, PyTorch-Lightning, — движками инференса — vLLM, SGLang, TGI, — а также смежными библиотеками, такими как llama.cpp и mlx.
Один раз добавил модель в Transformers — и она работает везде: в трейнере, инференс-движке и в квантизованном виде на локальном железе.
Transformers v5: большой структурный сдвиг
Hugging Face выпустила первый релиз-кандидат Transformers v5.0.0rc-0 — это значительный шаг в эволюции одной из самых широко используемых AI-библиотек, представляющий переход к простоте, интероперабельности и готовности к продакшену.
С момента выхода v4 число ежедневных установок выросло с 20 000 до более чем 3 миллионов через pip.
Ключевые изменения в v5
Transformers v5 включает серьёзный рефакторинг файлов моделей и токенизаторов: моделирование улучшено через модульный подход, токенизация упрощена до бэкенда tokenizers с удалением разделения на «Fast» и «Slow» токенизаторы, а поддержка Flax/TensorFlow прекращается в пользу PyTorch как единственного бэкенда.
Ещё одно ключевое изменение — квантизация как концепция первого класса: загрузка весов переработана для более естественной поддержки низкоточных форматов, поскольку многие современные модели поставляются в вариантах 8-bit или 4-bit.
Инференс в v5 улучшен за счёт streamlined API, continuous batching и paged attention. Введён компонент transformers serve для деплоя моделей через OpenAI-совместимый API.
Быстрый старт: Pipeline API
Pipeline — это высокоуровневый класс для инференса, поддерживающий задачи с текстом, аудио, зрением и мультимодальным контентом. Он берёт на себя предобработку входных данных и возвращает готовый результат.
Установка занимает одну команду:
pip install "transformers[torch]"
Пример генерации текста:
from transformers import pipeline
pipeline = pipeline(task="text-generation", model="Qwen/Qwen2.5-1.5B")
result = pipeline("Секрет вкусного торта — это ")
print(result[0]['generated_text'])
Пример распознавания речи (ASR — Automatic Speech Recognition):
from transformers import pipeline
pipeline = pipeline(task="automatic-speech-recognition", model="openai/whisper-large-v3")
pipeline("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
# {'text': ' I have a dream that one day this nation will rise up...'}
Как Transformers встраивается в экосистему
graph LR
A[Модель на HF Hub] --> B[transformers]
B --> C[Обучение]
B --> D[Инференс]
B --> E[Деплой]
C --> C1[Unsloth / Axolotl / TRL]
C --> C2[DeepSpeed / FSDP]
D --> D1[vLLM / SGLang / TGI]
D --> D2[llama.cpp / MLX]
E --> E1[transformers serve]
E --> E2[OpenAI-совместимый API]
Со временем Transformers стал центральным компонентом всей ML-экосистемы, будучи интегрированным во все популярные фреймворки обучения: Axolotl, Unsloth, DeepSpeed, FSDP, PyTorch-Lightning, TRL, Nanotron и другие.
Сравнение: когда использовать Transformers, а когда нет
| Сценарий | Transformers | Альтернатива |
|---|---|---|
| Загрузка и запуск SOTA-модели | ✅ Идеально | — |
| Fine-tuning с готовым Trainer | ✅ Да | — |
| Кастомные циклы обучения | ⚠️ Ограниченно | Accelerate |
| Продакшен-инференс на GPU-кластере | ⚠️ Базово | vLLM, SGLang |
| Модульные нейросетевые блоки | ❌ Не для этого | PyTorch напрямую |
| Мультифреймворковая совместимость | ✅ Да (через Hub) | — |
Значение для отрасли
Transformers v5 — это не столько про новые поверхностные возможности, сколько про укрепление роли библиотеки как общей инфраструктуры. Стандартизируя определения моделей и тесно интегрируясь с инструментами обучения, инференса и деплоя, Hugging Face позиционирует Transformers как стабильный «клей экосистемы» для следующей фазы открытой разработки AI.
По состоянию на 2025 год, Hugging Face доверяют более 50 000 организаций по всему миру, а экосистема продолжает расширяться. Transformers превратился из инструмента для исследователей в стандарт де-факто для всей индустрии: от стартапов до Google, Meta и Microsoft.
Transformers — это больше, чем инструментарий для работы с предобученными моделями, это целое сообщество проектов, выстроенных вокруг него и Hugging Face Hub.