LLMs с нуля: легендарный репозиторий на GitHub с 92К звёзд
Себастьян Рашка собрал в одном репозитории полный код для создания GPT-модели с нуля на PyTorch — от токенизации до fine-tuning с LoRA.
Репозиторий, который объясняет всё изнутри
GitHub-репозиторий rasbt/LLMs-from-scratch стал одним из самых популярных образовательных проектов в мире AI: более 92 тысяч звёзд и 14 тысяч форков — цифры, которые говорят сами за себя. Автор — Себастьян Рашка (Sebastian Raschka), исследователь в области LLM. В книге и коде вы узнаете, как работают большие языковые модели изнутри, шаг за шагом написав их с нуля. Главная идея проста: понять можно только то, что построил сам.
Подход: зеркало ChatGPT для образования
Метод, описанный в книге, зеркально отражает подход, используемый при создании крупных фундаментальных моделей, таких как те, что лежат в основе ChatGPT. При этом код из основных глав рассчитан на запуск на обычном ноутбуке без специализированного железа, а GPU используется автоматически, если он доступен.
Без опоры на существующие LLM-библиотеки вы кодируете базовую модель, превращаете её в текстовый классификатор и в итоге создаёте чат-бота, который следует разговорным инструкциям.
«Я не понимаю того, что не могу построить» — Ричард Фейнман. Именно этот принцип лежит в основе книги Рашки.
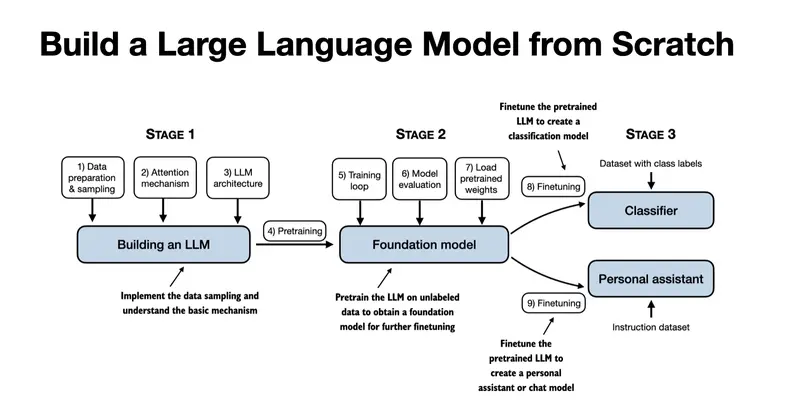
Структура курса: 7 глав и 5 приложений
Репозиторий строго следует структуре книги. Каждая глава — отдельная директория с Jupyter-ноутбуком, скриптами и решениями упражнений.
| Глава | Тема | Ключевые файлы |
|---|---|---|
| Ch 2 | Working with Text Data | ch02.ipynb, dataloader.ipynb |
| Ch 3 | Coding Attention Mechanisms | ch03.ipynb, multihead-attention.ipynb |
| Ch 4 | Implementing a GPT Model | ch04.ipynb, gpt.py |
| Ch 5 | Pretraining on Unlabeled Data | gpt_train.py, gpt_generate.py |
| Ch 6 | Finetuning for Classification | gpt_class_finetune.py |
| Ch 7 | Finetuning to Follow Instructions | gpt_instruction_finetuning.py |
Приложения охватывают введение в PyTorch (Appendix A), параметрически эффективный fine-tuning с LoRA (Appendix E) и настройку тренировочного цикла (Appendix D).
Маршрут от токена до модели
Ниже — упрощённая схема того, как выстроен путь обучения:
graph TD
A[Текстовые данные / Tokenization] --> B[Attention Mechanisms]
B --> C[GPT Model Architecture]
C --> D[Pretraining на сырых данных]
D --> E[Fine-tuning: классификация]
D --> F[Fine-tuning: следование инструкциям]
E --> G[Готовая LLM на ноутбуке]
F --> G
Бонусные материалы: от Llama до MoE
Помимо основных глав, репозиторий содержит обширную коллекцию дополнительных ноутбуков. Среди них — реализации современных архитектур:
- Llama 3.2 From Scratch
- Qwen3 Dense и Mixture-of-Experts (MoE — смесь экспертов) From Scratch
- Gemma 3 / Gemma 4 From Scratch
- Olmo 3 From Scratch
- Grouped-Query Attention, Multi-Head Latent Attention, Sliding Window Attention
- KV Cache, FLOPs-анализ
Это превращает репозиторий из учебного пособия в живую коллекцию актуальных архитектурных решений.
Быстрый старт
git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git
cd LLMs-from-scratch
# Открывайте нужную главу, например:
jupyter notebook ch02/01_main-chapter-code/ch02.ipynb
Продолжение: reasoning-модели
В 2025 году Рашка выпустил книгу-продолжение. «Build A Reasoning Model (From Scratch)» можно считать сиквелом: она начинается с pretrained-модели и реализует разные подходы к рассуждению — inference-time scaling, reinforcement learning и дистилляцию. Описываемые методы зеркалят подходы, используемые в таких моделях, как DeepSeek R1 и GPT-5 Thinking.
Почему это важно для отрасли
В момент, когда большинство реализаций LLM используют высокоуровневые пакеты вроде transformers, особенно ценно видеть прогрессивное построение модели через базовые элементы PyTorch. Репозиторий Рашки закрывает критический пробел: между «использую ChatGPT» и «понимаю, как он работает». Себастьян Рашка — Staff Research Engineer в Lightning AI, где занимается исследованиями LLM и разработкой open-source ПО. Его работа доказывает, что самый лучший способ понять технологию — это построить её самостоятельно.