OpenAI Whisper: распознавание речи на 99 языках с открытым кодом
Разбираем OpenAI Whisper — мощную open-source модель для распознавания речи, перевода и транскрипции на 99 языках с моделями от tiny до turbo.
OpenAI Whisper: распознавание речи на 99 языках с открытым кодом
OpenAI открыла доступ к Whisper — универсальной модели для распознавания речи, которая умеет транскрибировать аудио на 99 языках, переводить речь в текст и определять язык говорящего. Всё это в одной модели с открытым исходным кодом и MIT-лицензией. Последнее поколение — Whisper Large V3 Turbo — работает в 8 раз быстрее предшественника при минимальной потере точности.
Что такое Whisper
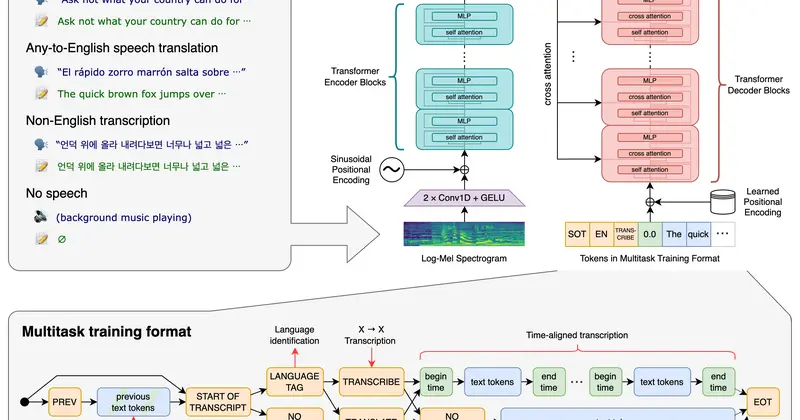
Whisper — это система автоматического распознавания речи (ASR), обученная на 680 000 часах многоязычных и многозадачных данных, собранных из интернета. Использование такого большого и разнообразного датасета улучшает устойчивость к акцентам, фоновому шуму и техническому жаргону, а также позволяет транскрибировать аудио на множестве языков и переводить речь на английский.
В основе — Transformer-модель типа sequence-to-sequence, обученная на множестве задач: многоязычное распознавание речи, перевод, определение языка и детекция голосовой активности. Все задачи представлены единым потоком токенов, что позволяет одной модели заменить сразу несколько этапов традиционного pipeline обработки речи.
Линейка моделей: от tiny до turbo
Whisper — это целое семейство моделей: размер, язык и качество аудио существенно влияют на точность. Доступны размеры от Tiny (39 млн параметров) до Large-v3 (1,5 млрд).
| Модель | Параметров | Только EN | Многоязычная | VRAM | Скорость |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~10x |
| base | 74 M | base.en | base | ~1 GB | ~7x |
| small | 244 M | small.en | small | ~2 GB | ~4x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1 550 M | — | large | ~10 GB | 1x |
| turbo | 809 M | — | turbo | ~6 GB | ~8x |
Turbo — оптимальный выбор для большинства задач: скорость большой модели при точности, сопоставимой с large-v2.
Что такое Whisper Turbo
Whisper Large V3 Turbo — последняя на момент написания модель Whisper, выпущенная OpenAI в октябре 2024 года. Она сохраняет точность модели Large V2, но значительно увеличивает скорость обработки.
Whisper large-v3-turbo — это дообученная версия «обрезанного» Whisper large-v3: та же архитектура, но количество слоёв декодера сокращено с 32 до 4, что делает модель значительно быстрее ценой незначительного снижения качества.
Идея вдохновлена проектом Distil-Whisper, авторы которого установили, что уменьшенный декодер существенно ускоряет транскрипцию при минимальной потере точности. В отличие от дистилляции, Whisper Turbo дообучался ещё два эпохи на тех же данных, что использовались для large-v3.
medium или large. Turbo вернёт текст на исходном языке даже при флаге --task translate.Точность и сравнение
Whisper Large-v3 достигает 2,7% WER (word error rate — процент ошибочно распознанных слов) на чистом аудио, и 8–12% в реальных условиях.
На английском языке Whisper достигает 5–6% WER, опережая Microsoft Azure и Google Speech-to-Text на тестах с записями совещаний. Точность падает для сложных языков и шумных условий, например в колл-центрах.
Несмотря на наличие конкурентов, Whisper остаётся наиболее широко применяемой open-source ASR-моделью благодаря зрелой экосистеме, охвату языков и доступности оптимизированных рантаймов вроде whisper.cpp.
Как работает пайплайн
graph TD
A[Аудио файл\nMP3 / WAV / FLAC] --> B[Разбивка на 30-сек чанки]
B --> C[log-Mel спектрограмма]
C --> D[Transformer Encoder]
D --> E[Transformer Decoder]
E --> F{Задача}
F -->|Транскрипция| G[Текст на исходном языке]
F -->|Перевод| H[Текст на английском]
F -->|Идентификация| I[Определение языка]
Быстрый старт
Установка
# Установка через pip
pip install -U openai-whisper
# Также нужен ffmpeg
# Ubuntu/Debian:
sudo apt update && sudo apt install ffmpeg
# MacOS:
brew install ffmpeg
# Windows (Chocolatey):
choco install ffmpeg
Использование из командной строки
# Транскрипция (модель turbo по умолчанию)
whisper audio.mp3 --model turbo
# Транскрипция на японском
whisper japanese.wav --language Japanese
# Перевод на английский (только multilingual-модели!)
whisper japanese.wav --model medium --language Japanese --task translate
Использование из Python
import whisper
model = whisper.load_model("turbo")
result = model.transcribe("audio.mp3")
print(result["text"])
- Нет GPU →
tinyилиbase(работают на CPU, ~1 GB RAM) - Обычные задачи →
turbo(лучший баланс скорости и точности) - Нужен перевод →
mediumилиlarge - Максимальная точность →
large-v3
Цена и лицензия
Код и веса модели Whisper опубликованы под лицензией MIT. Это означает свободное коммерческое использование, модификацию и встраивание в продукты.
После загрузки модели Whisper работает полностью локально без подключения к интернету, что делает его подходящим для приложений с повышенными требованиями к конфиденциальности, офлайн-сред и изолированных систем.
API-версия стоит $0,006 за минуту — примерно вчетверо дешевле Amazon Transcribe и вдвое дешевле Google Cloud Speech-to-Text.
Контекст и значение для отрасли
По данным Quantumrun, Large-v3 модель Whisper набирает 4,09 млн ежемесячных загрузок на Hugging Face по состоянию на декабрь 2024 года. Глобальный рынок распознавания речи достиг $8,49 млрд в том же году и, по прогнозам, вырастет до $23,11 млрд к 2030 году с темпом роста 19,1% в год.
На базе Whisper OpenAI также выпустила GPT-Realtime-Whisper — новую потоковую модель транскрипции с низкой задержкой для работы в реальном времени: она транскрибирует аудио прямо в процессе речи, что позволяет создавать более быстрые и отзывчивые продукты.
- Субтитры и подписи к видео в реальном времени
- Транскрипция встреч и интервью
- Голосовые ассистенты и чат-боты с речевым вводом
- Медицина и юриспруденция — документирование устной речи
- Доступность — помощь людям с нарушениями слуха
Whisper задал новую планку для open-source ASR: модель, обученная на масштабных слабо размеченных данных, оказалась более универсальной и устойчивой, чем узкоспециализированные системы предыдущего поколения. С выходом Turbo барьер для использования в продакшене стал ещё ниже.